
Imitation learning empowers artificial agents to mimic behavior by learning from demonstrations. Recently, diffusion models have shown impressive performance on imitation learning tasks. These models learn to shape a policy by diffusing actions (or states) from standard Gaussian noise.
Unfortunately, diffusion models are often slow. To speed things up, one can decrease the number of diffusion steps, but this often results in poor performance. For complex tasks, diffusion methods also require a fair bit of data.
In this work, we improve diffusion policies to perform better with fewer diffusion steps and less data. The key idea underlying our work is that initiating from a more informative source than Gaussian enables better imitation learning! For the cleaning task shown below, our method (BRIDGeR) significantly outperforms state-of-the-art diffusion policies with 5 diffusion steps.
We contribute theoretical results, a new method, and empirical findings that show the benefits of using an informative source policy. BRIDGeR builds upon the stochastic interpolants framework to bridge arbitrary policies. BRIDGER transports actions from source distribution to the target distribution via a forward SDE, as shown below.
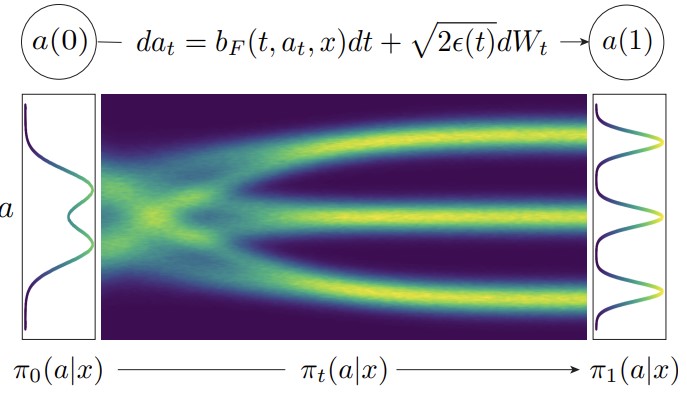
BRIDGeR enables a flexible approach towards imitation learning and generalizes prior work in that standard Gaussians can still be applied, but other source policies can be used if available. We show that BRIDGeR performs well in both challenging simulation and real-world experiments.

The image below shows results from 6DoF robot grasp generation. We use a simple source policies: (1) a CVAE policy, and (2) a simple heuristic policy randomly samples pointing towards the center of the object. With only 10 diffusion steps, BRIDGeR is able to generate successful grasps (better than state-of-the-art SE3 diffusion).
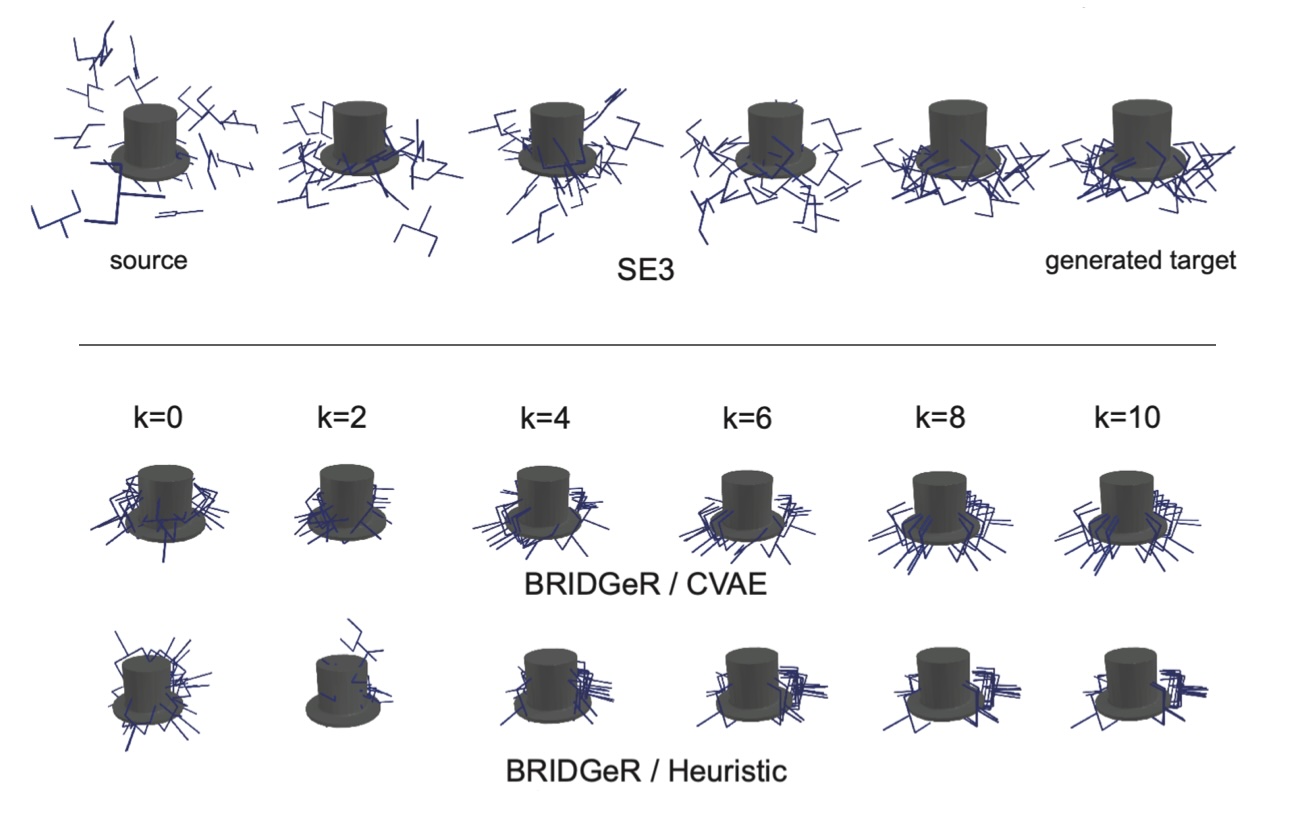
For more results, please see our our paper.
Code
Code for reproducing our experiments can be found in our Github repo.
Citation
If you find our code or the ideas presented in our paper useful for your research, consider citing our paper.
Kaiqi Chen★, Eugene Lim★ , Kelvin Lin★, Yiyang Chen★, and Harold Soh★. “Don’t Start from Scratch: Behavioral Refinement via Interpolant-based Policy Diffusion” 2024 Robotics-Science and Systems (R:SS 2024).*
@article{chen2024behavioral,
title={Don’t Start from Scratch: Behavioral Refinement via Interpolant-based Policy Diffusion},
author={Chen, Kaiqi and Lim, Eugene and Lin, Kelvin and Chen, Yiyang and Soh, Harold},
journal={arXiv preprint arXiv:2402.16075},
year={2024}
}
Contact
If you have questions or comments, please contact Kaiqi Chen or Harold.





{kind=link}