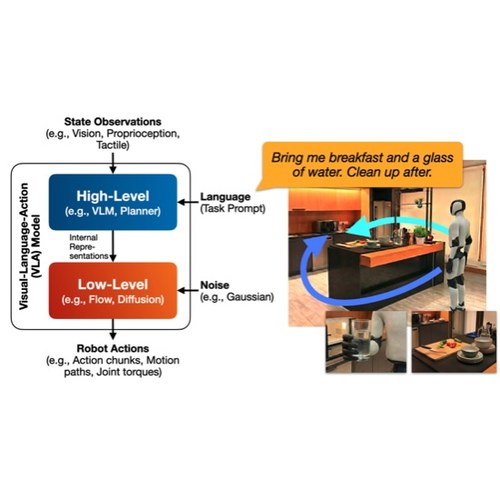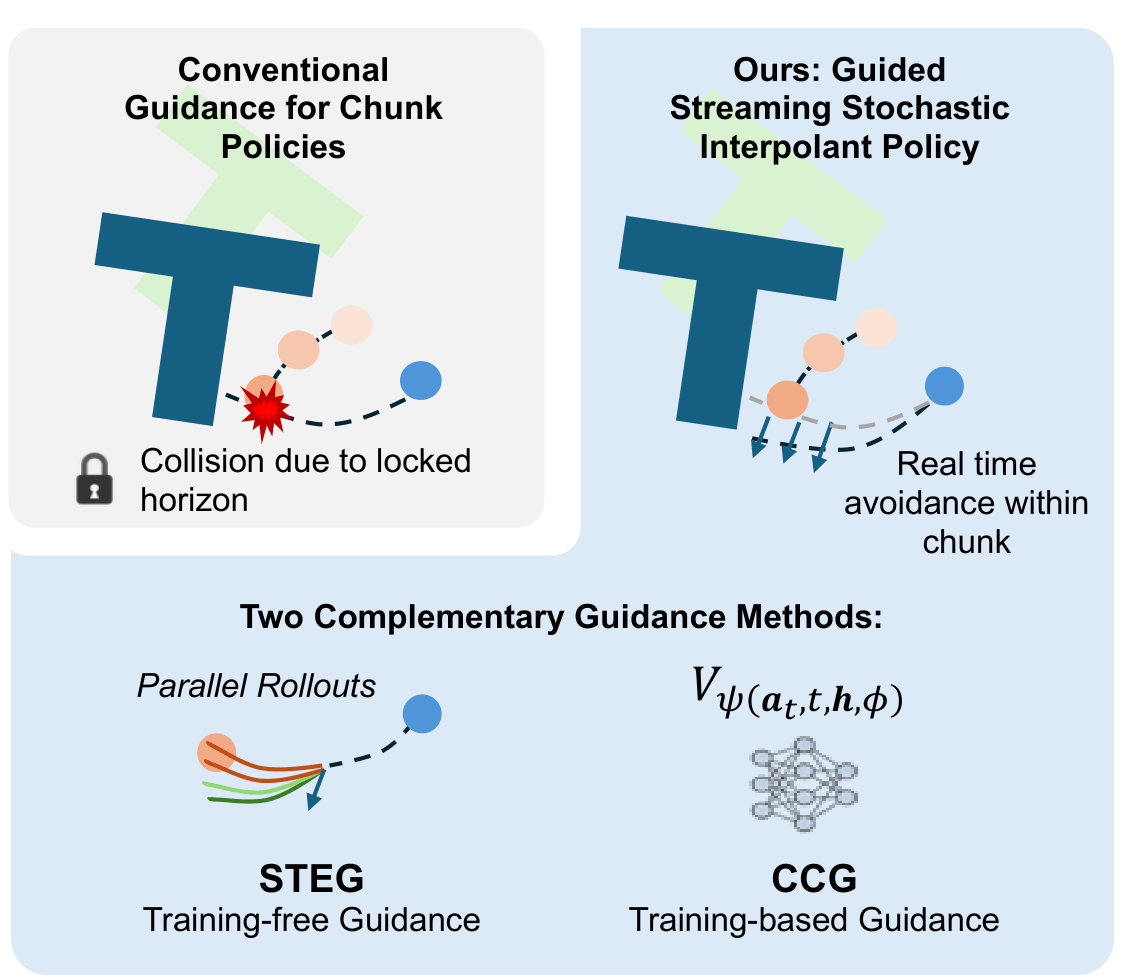
Guided Streaming Stochastic Interpolant Policy
A principled inference-time guidance framework for streaming generative robot policies, enabling fast, reactive obstacle avoidance within the action chunk.

Collaborative, Learning, and Adaptive Robots Lab at NUS.
We develop Trustworthy Robots.
A principled inference-time guidance framework for streaming generative robot policies, enabling fast, reactive obstacle avoidance within the action chunk.
Skill Mixture-of-Experts Policy (SMP)—a diffusion mixture-of-experts policy that learns a compact orthogonal skill basis and uses sticky routing for scalable, efficient multi-task manipulation.
We introduce PhysiCLeaR, an annotated dataset of everyday objects and tactile readings collected from a Gelsight Mini sensor, as well as Octopi, a system that leverages both tactile representation learning and large vision-language models to perform physical reasoning and inference, given tactile videos of multiple objects.
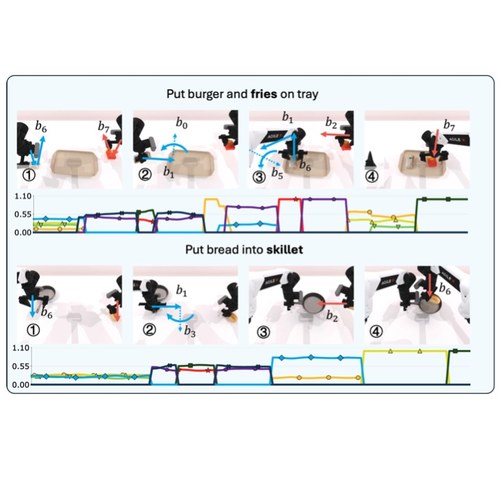
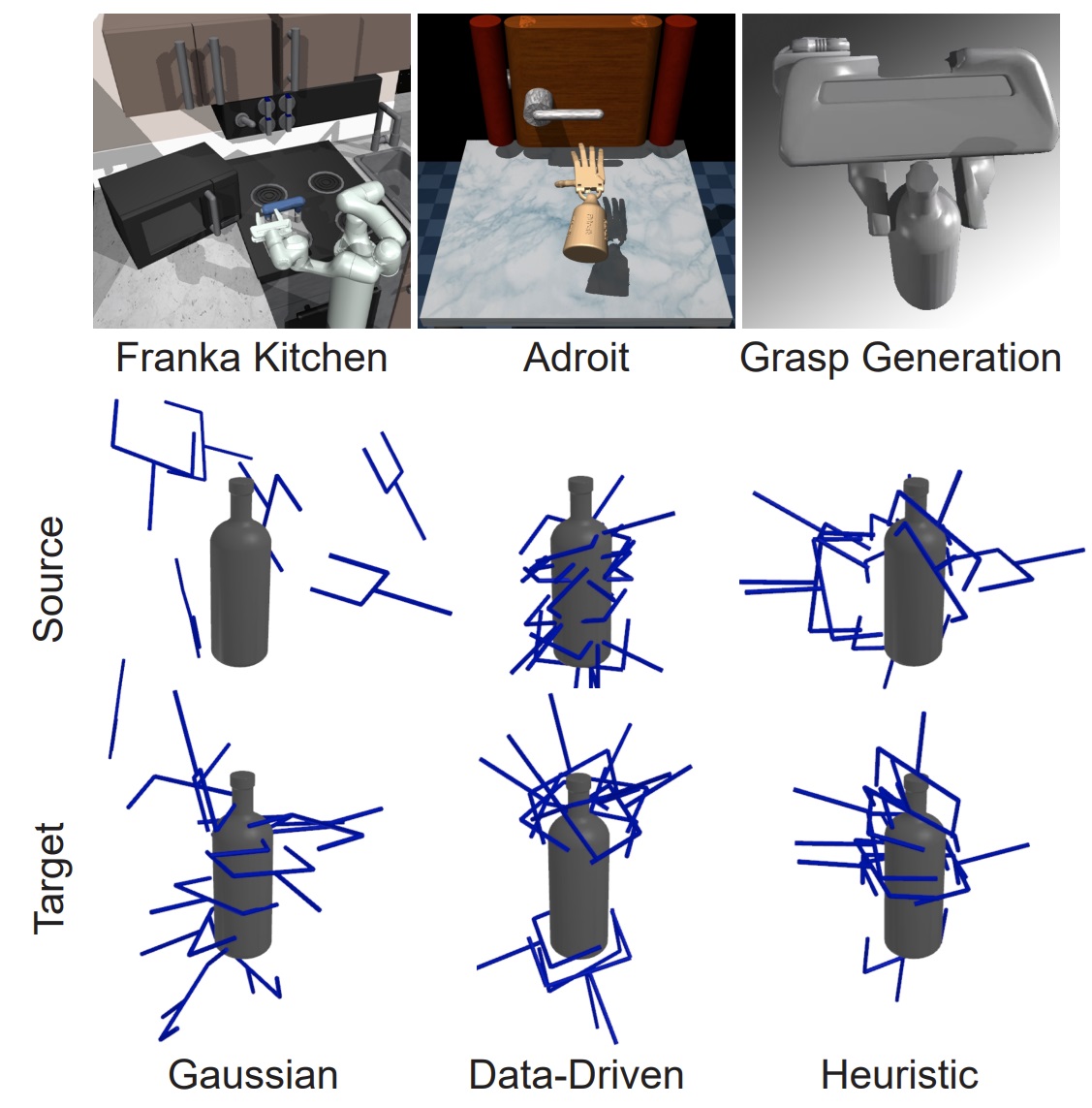
We develop interpolant policies that leverage informative source distributions for imitation learning.
CLeAR took Overall Champion at REAL-I 2026, the 1st Real-World Embodied AI Learning Challenge, held at ICRA 2026.
We are excited to share that a paper from CLeAR has been accepted to ICML 2026! Here’s a snapshot: Conflict-Aware Additive Guidance for Flow Models under Co...
We are excited to share that two papers from CLeAR were accepted to R:SS 2026! More information about the papers is coming soon, but here’s a snapshot: ...
Ce Hao has graduated and is now Dr. Hao. Congratulations Ce! Ce’s PhD thesis, Advanced Diffusion Robot Manipulation Policies for Language Reasoning, Long-Ho...
A dual-arm manipulation framework that enables skill reuse—recomposing learned single-arm skills into novel left–right pairings to tackle combinatorial diversity.
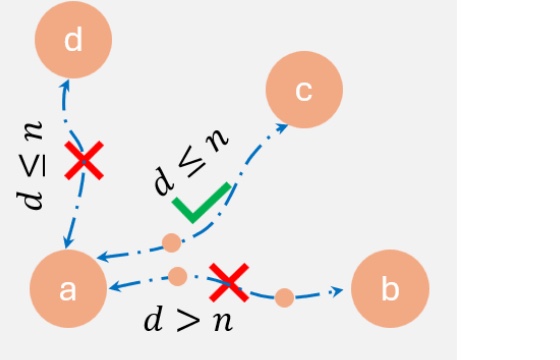
We introduce a plug-and-play module that corrects off-manifold drift when guiding flow models with multiple rewards at inference time.
A self-supervised tactile backbone that learns shared representations across heterogeneous tactile sensors, boosting perception and contact-rich manipulation—even with sensors unseen during pretraining.
An open-source framework for evaluating topological mapping, with the first quantitative measure of dataset ambiguity (perceptual aliasing).
A theoretical analysis of why generative VLAs produce physically infeasible actions, identifying topological, precision, and horizon barriers that impose unavoidable tradeoffs.