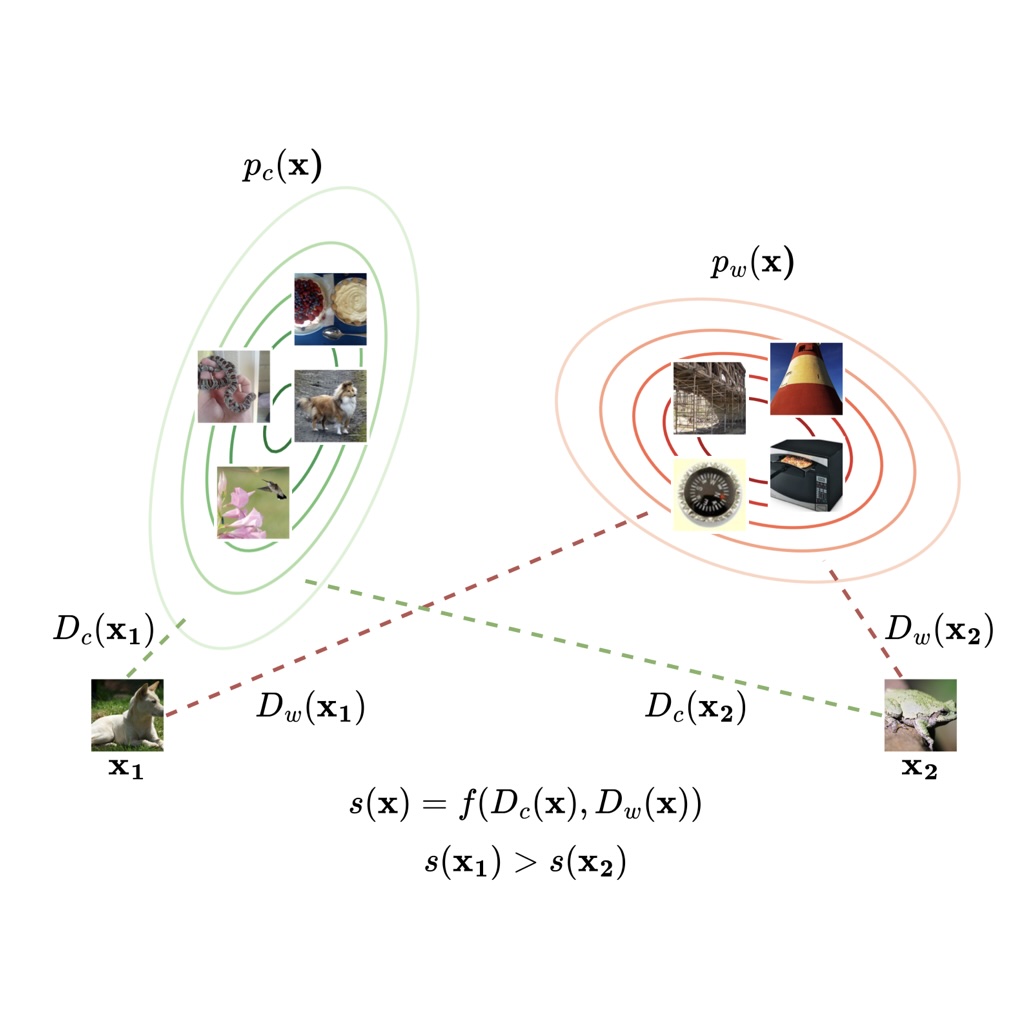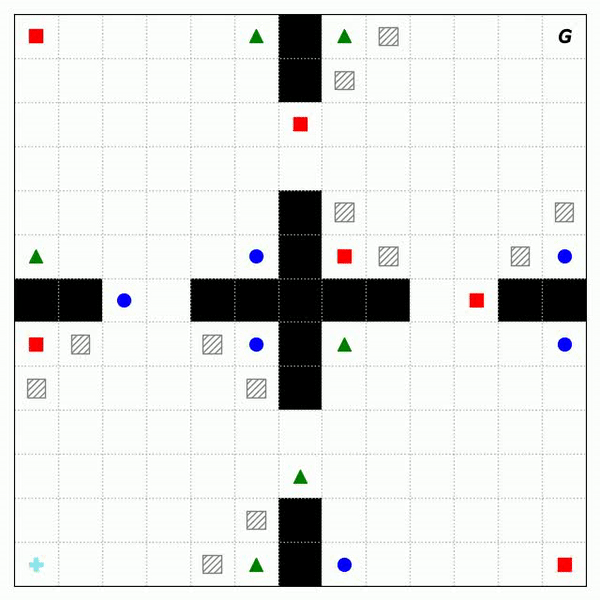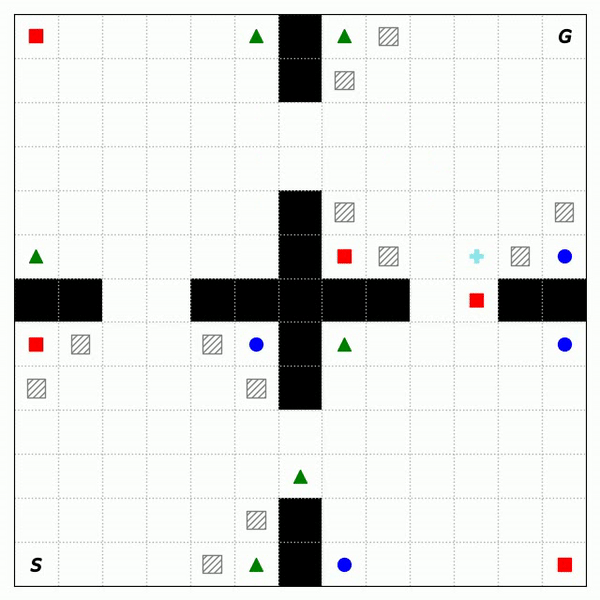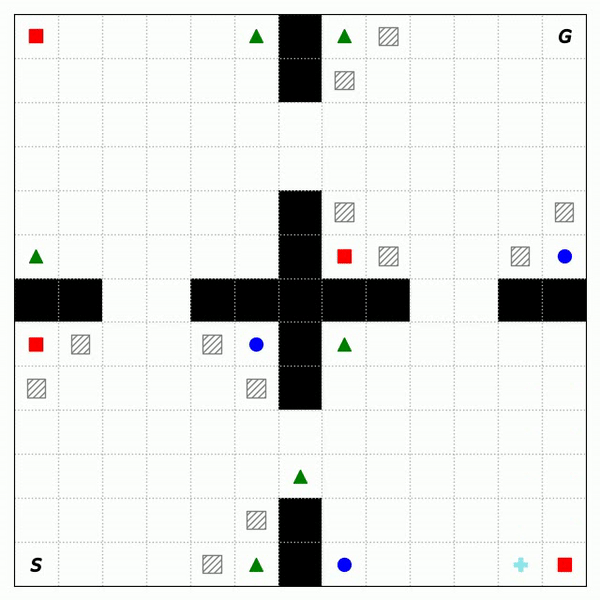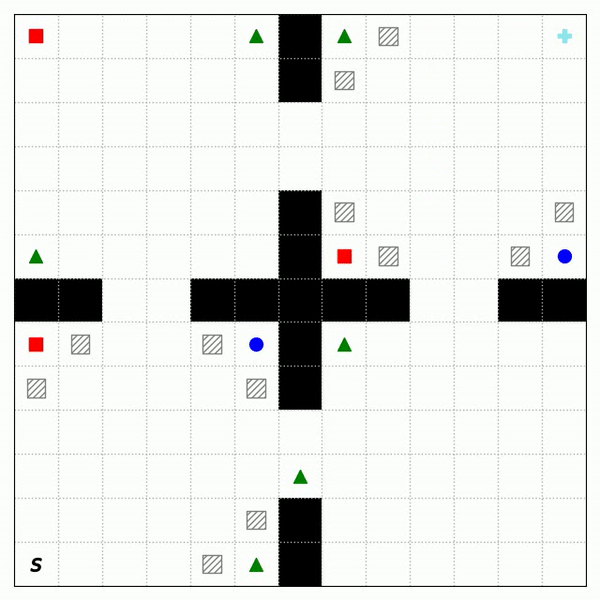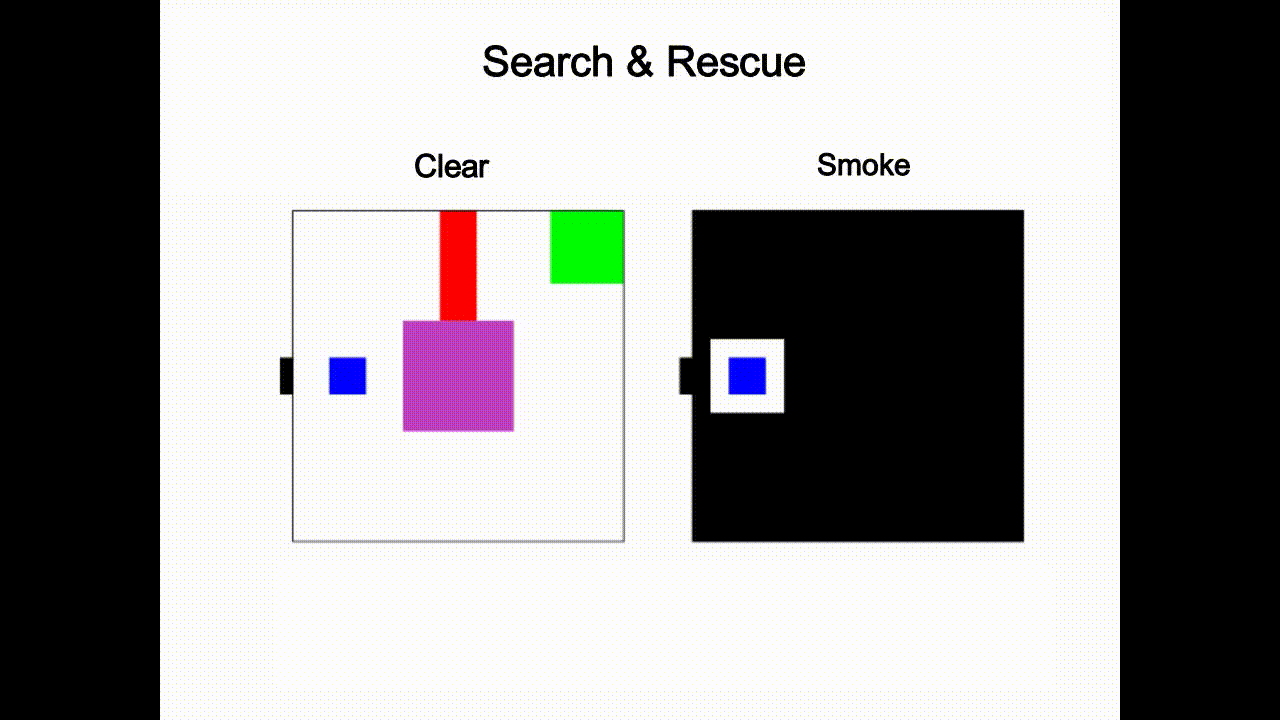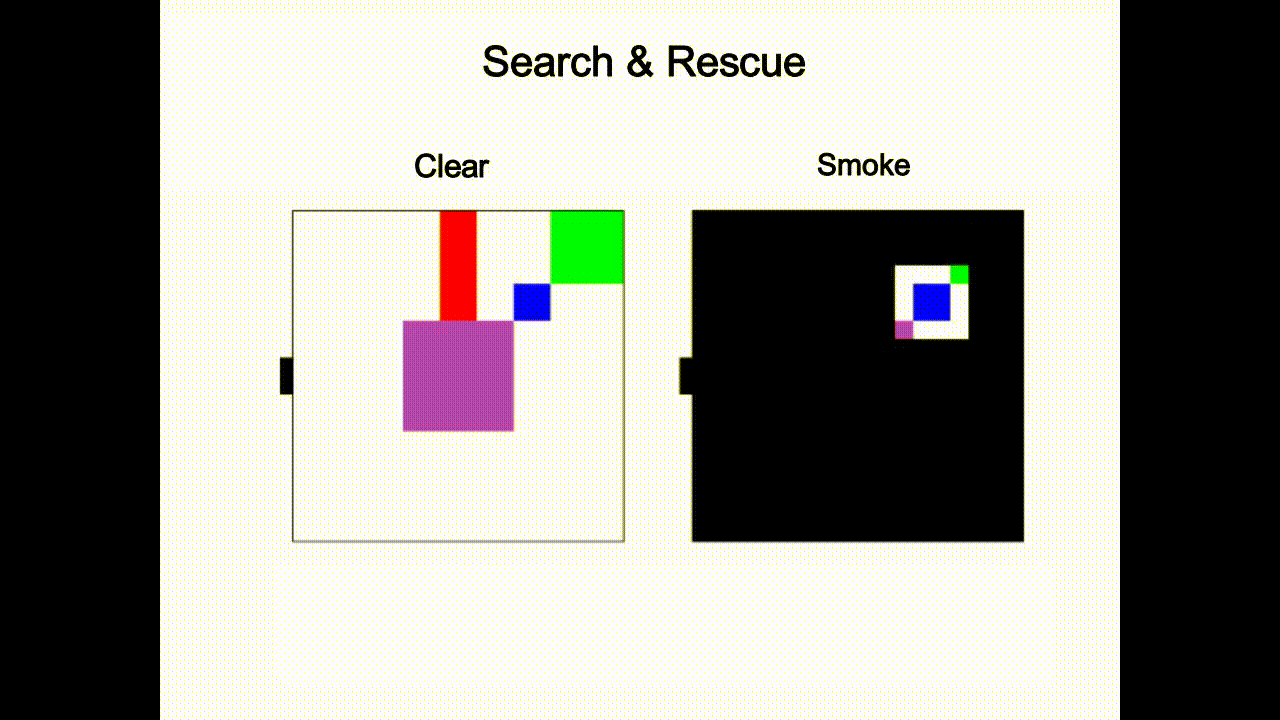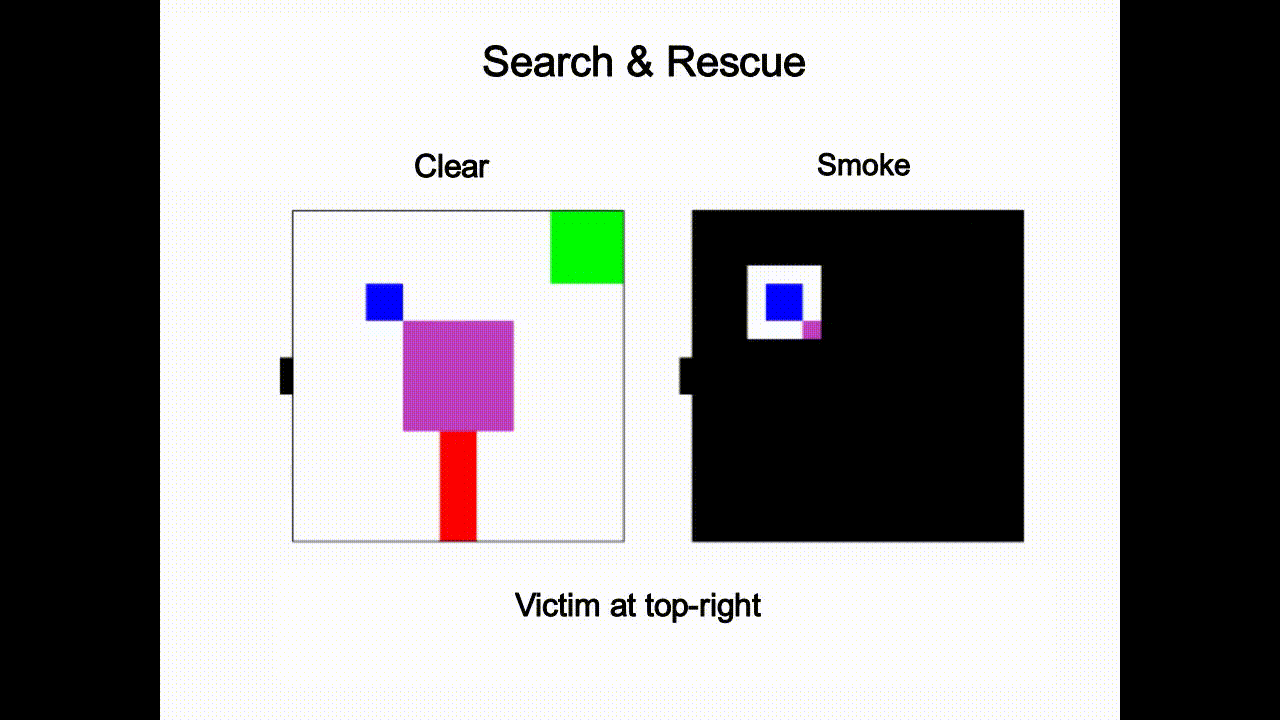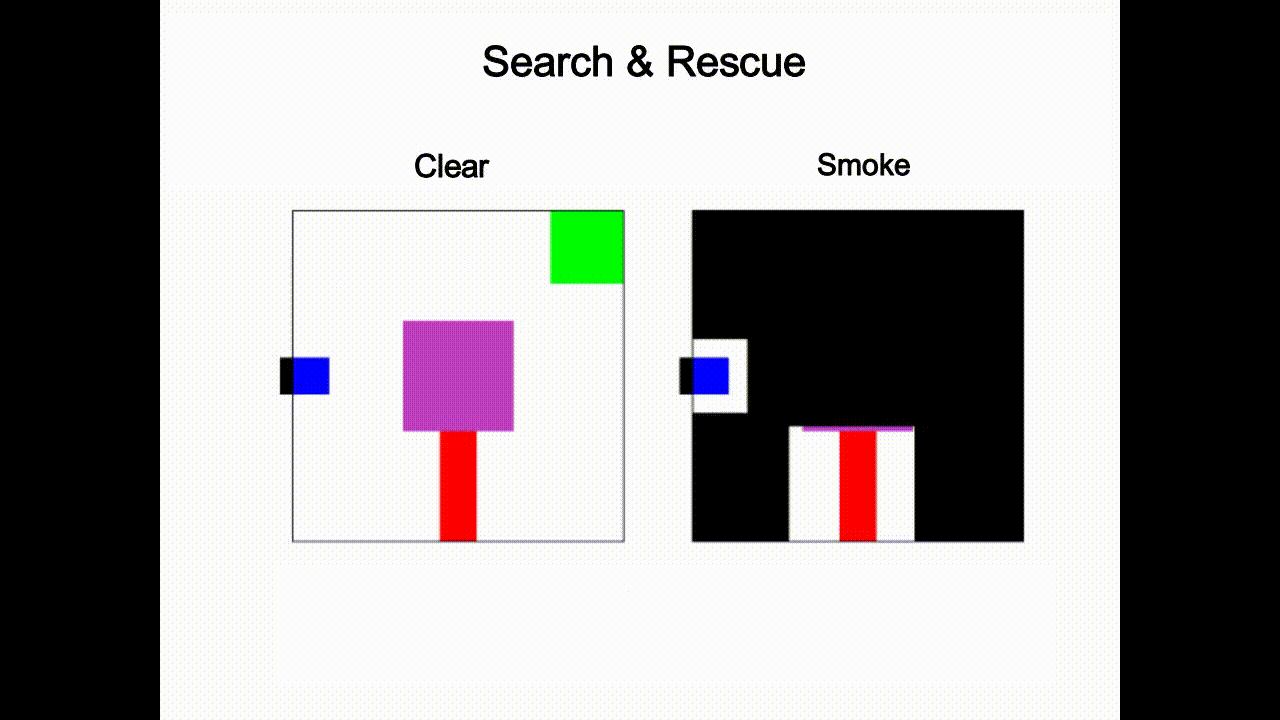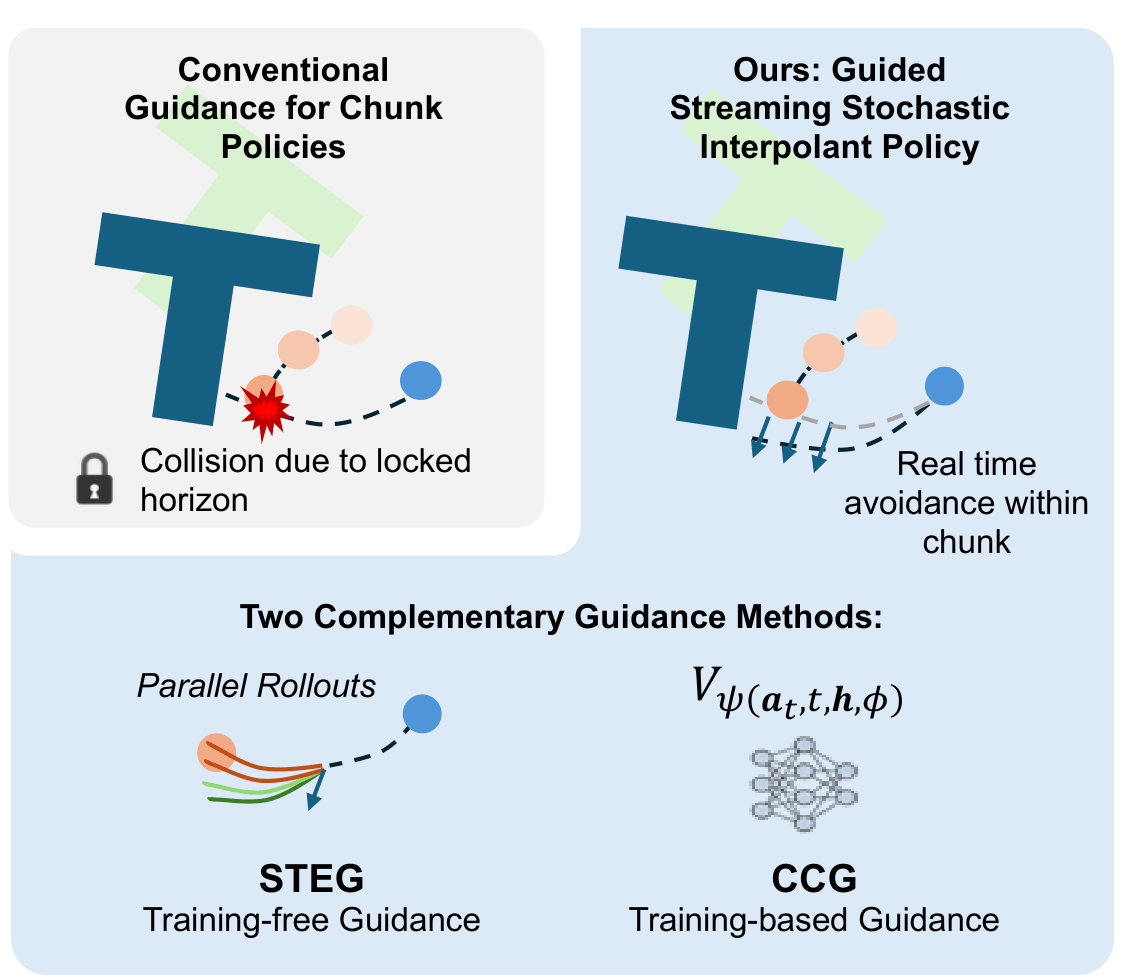
Guided Streaming Stochastic Interpolant Policy
A principled inference-time guidance framework for streaming generative robot policies, enabling fast, reactive obstacle avoidance within the action chunk.

Collaborative Learning and Adaptive Robots (CLeAR) Lab.
Below, you’ll find our contributions to robot/machine learning. Much of our work is on learning from (or interacting with) humans.
A principled inference-time guidance framework for streaming generative robot policies, enabling fast, reactive obstacle avoidance within the action chunk.
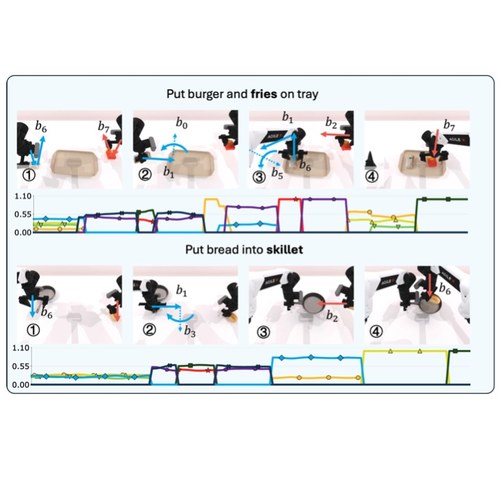
A dual-arm manipulation framework that enables skill reuse—recomposing learned single-arm skills into novel left–right pairings to tackle combinatorial diversity.
We introduce a plug-and-play module that corrects off-manifold drift when guiding flow models with multiple rewards at inference time.
A self-supervised tactile backbone that learns shared representations across heterogeneous tactile sensors, boosting perception and contact-rich manipulation—even with sensors unseen during pretraining.
An open-source framework for evaluating topological mapping, with the first quantitative measure of dataset ambiguity (perceptual aliasing).
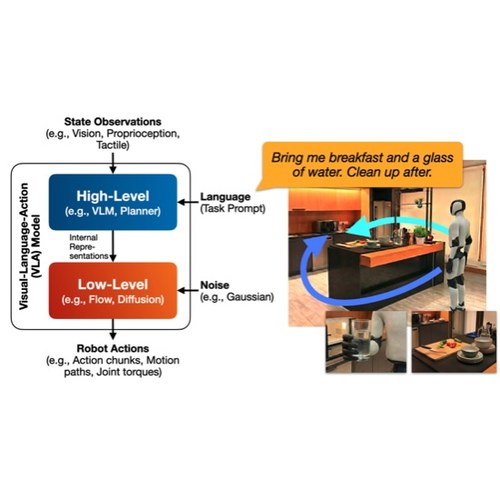
A theoretical analysis of why generative VLAs produce physically infeasible actions, identifying topological, precision, and horizon barriers that impose unavoidable tradeoffs.
Skill Mixture-of-Experts Policy (SMP)—a diffusion mixture-of-experts policy that learns a compact orthogonal skill basis and uses sticky routing for scalable, efficient multi-task manipulation.
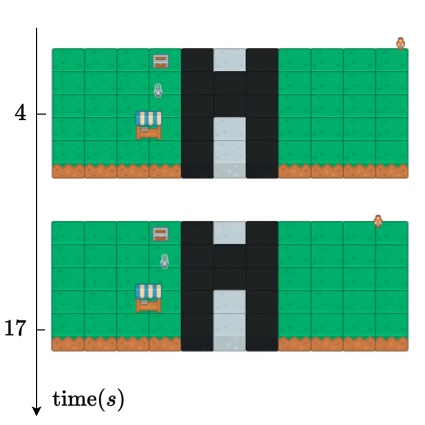
We present a robust navigation framework designed for global deployment that achieved first place in the Earth Rover Challenge at ICRA 2025.
We present VLA-Touch, a framework for VLA models with dual-level tactile feedback for contact-rich manipulation.
DOPPLER is a new framework that combines diffusion models and hierarchical reinforcement learning to let robots plan and replan complex, long-horizon tasks from offline data with robustness in the real world.
We propose optimal likelihood ratio-based selective classification methods based on the Neyman-Pearson lemma and evaluate them under vision and language covariate shifts tasks.
We show that a single unconditional diffusion model performs competitively in out-of-distribution detection tasks by measuring the rate-of-change and curvature of diffusion paths connecting data samples to the standard normal distribution.
We address a problem where an agent assigns users to arms in a stochastic multi-armed bandit setting to maximize the minimum expected cumulative reward for all users. It presents a UCB-based policy with upper bounds on cumulative regret and an impossibility result for policy-independent approaches.
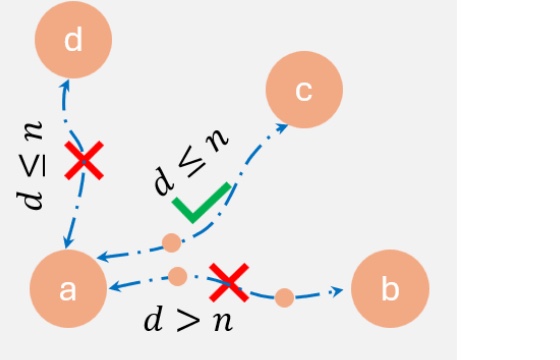
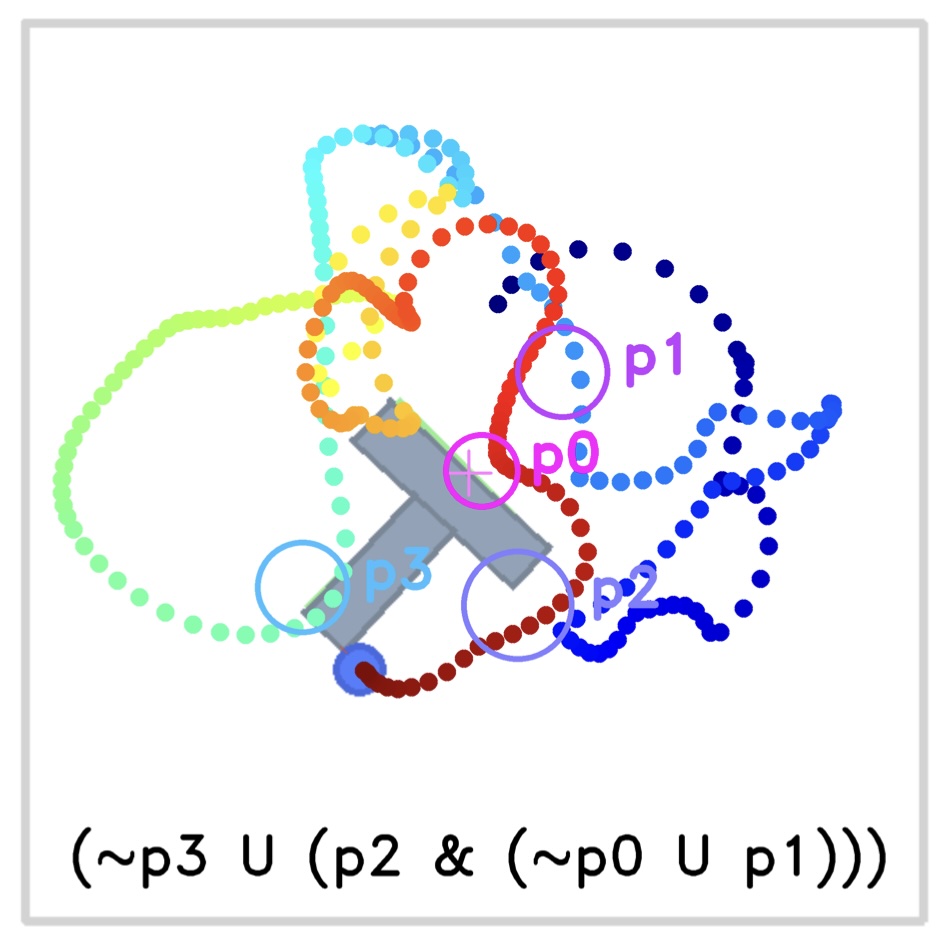
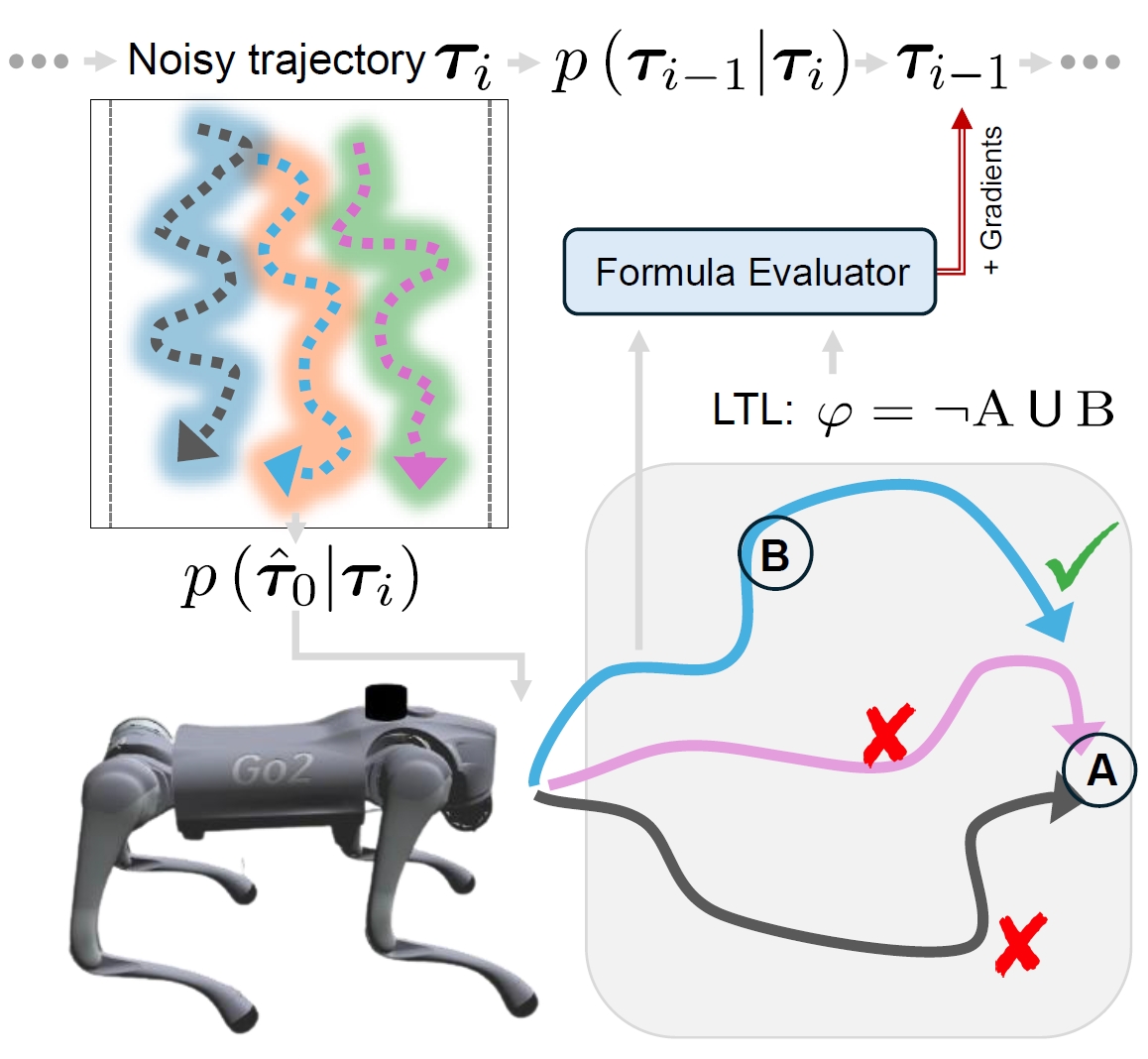
We develop a safe planning method for trajectory generation by sampling from diffusion model under different LTLf constraints.
We extend gradient flow methods to a variety of high-quality image synthesis tasks using a novel density ratio learning method.
We introduce PhysiCLeaR, an annotated dataset of everyday objects and tactile readings collected from a Gelsight Mini sensor, as well as Octopi, a system that leverages both tactile representation learning and large vision-language models to perform physical reasoning and inference, given tactile videos of multiple objects.
We develop interpolant policies that leverage informative source distributions for imitation learning.
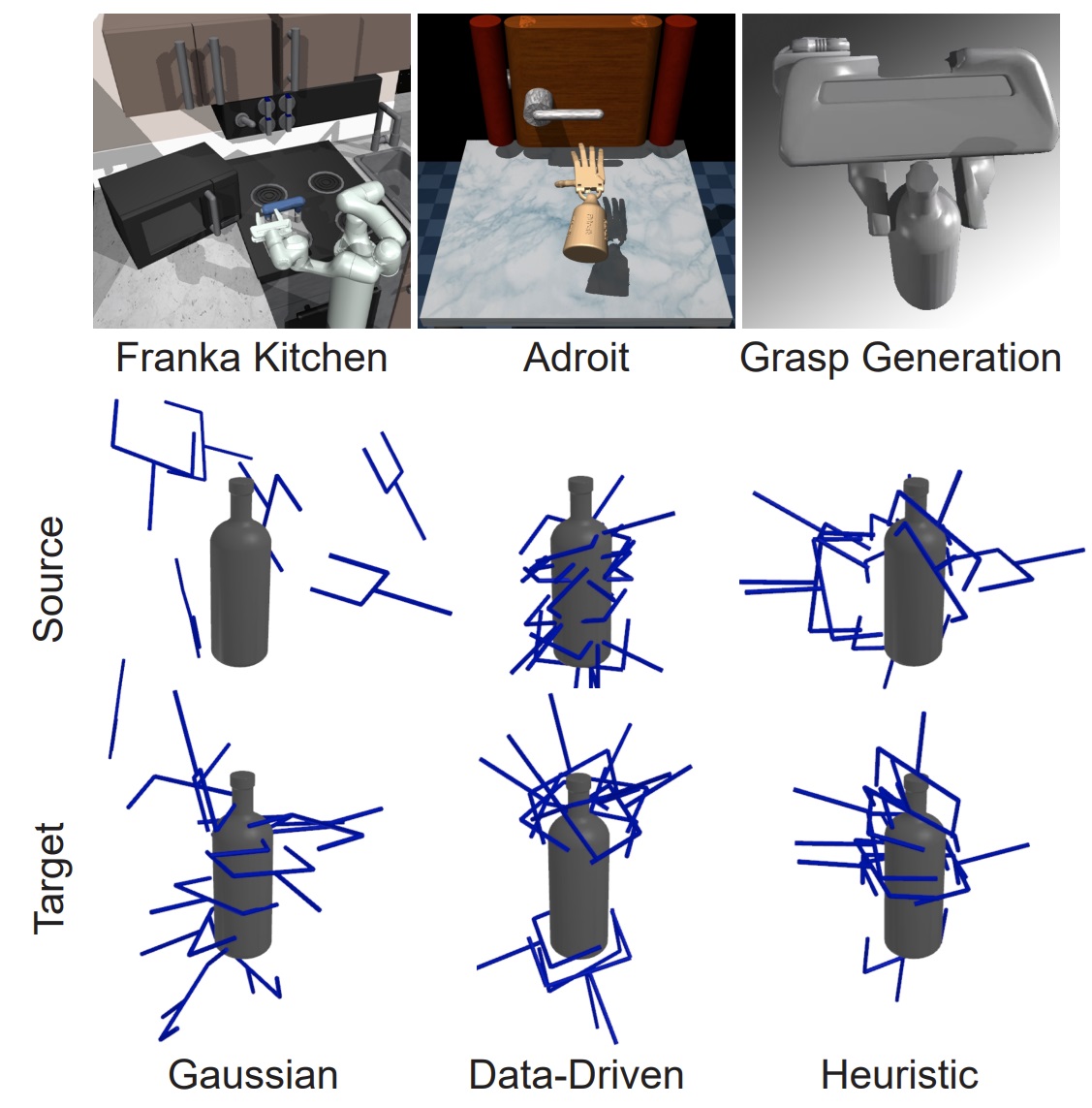
We propose an optimization-based grasp synthesis framework, GRaCE, to generate context-specific grasps in complex scenarios. We test GRaCE in a simulator and a real-world grasping tasks.
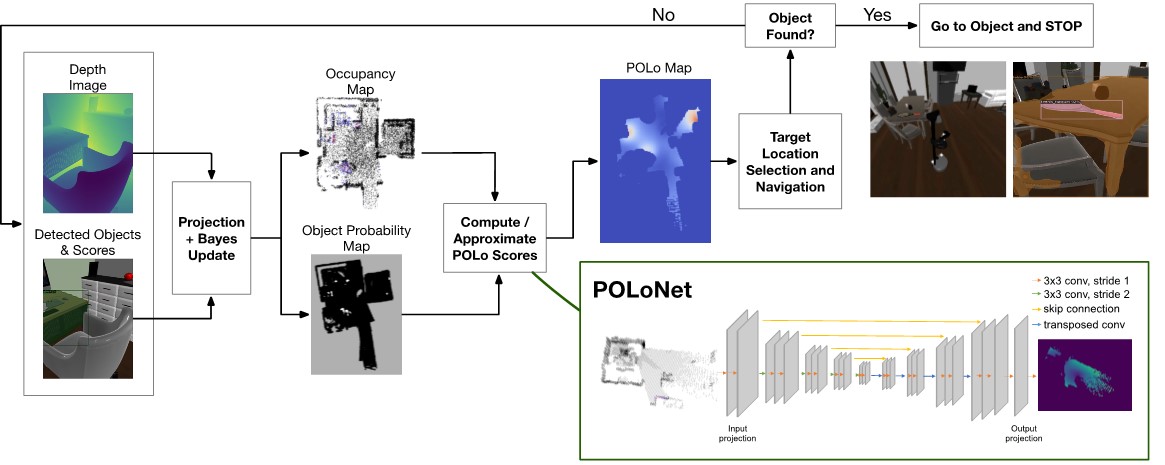
We introduce a novel framework centered around the Probable Object Location (POLo) score, which allows the agent to make data-driven decisions for efficient object search.
We apply techniques from continual learning to the problem of selective forgetting in deep generative models. Our method, dubbed Selective Amnesia, allows users to remap undesired concepts to user-defined ones.
We study a model of multi-population learning with heterogenous beliefs.
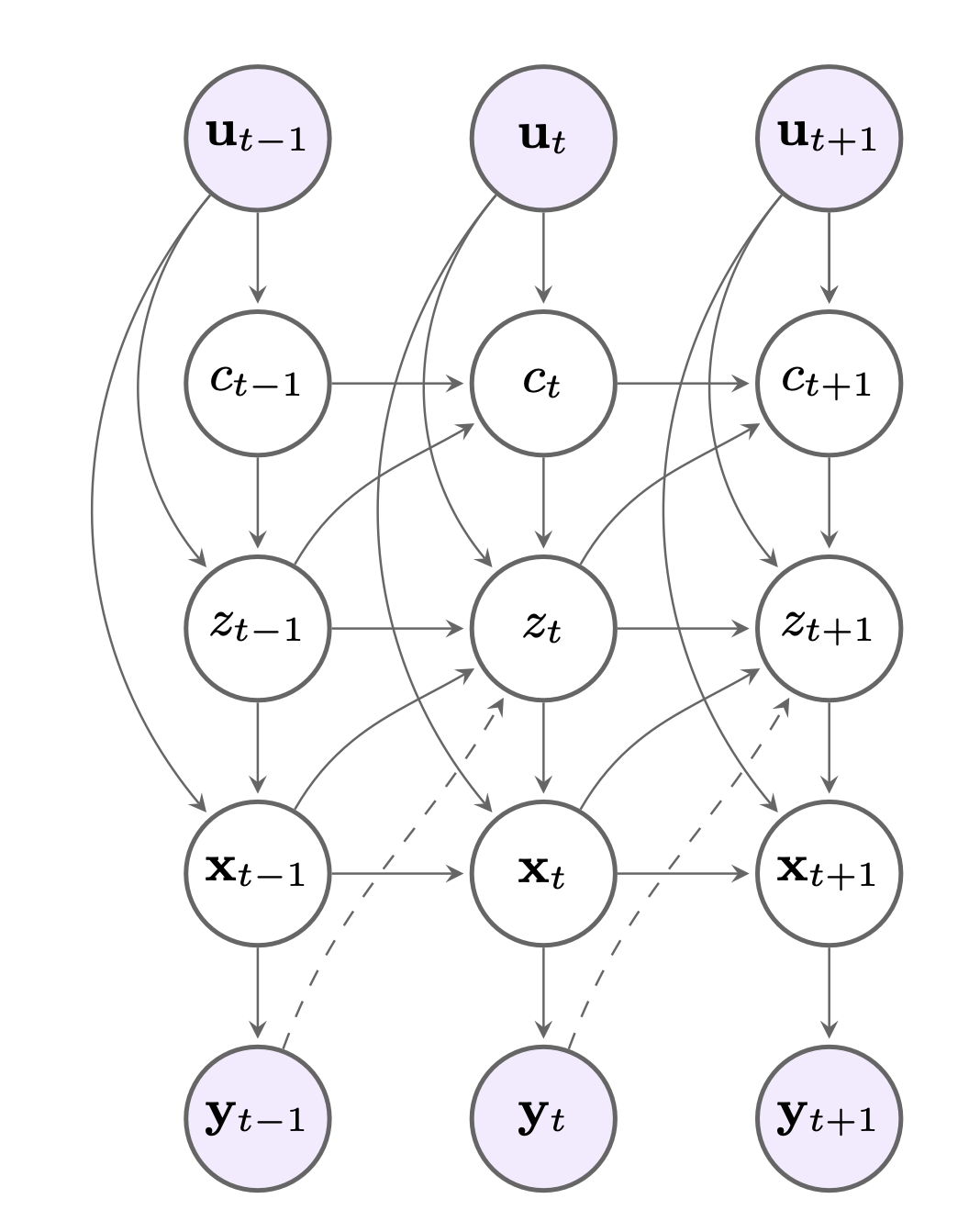
We construct a decomposed latent state space model for perspective-taking for human robot interaction.
We explore the potential of LLMs to act as zero-shot human models for HRI. We contribute an empirical study and case studies on a simulated table-clearing task and a new robot utensil-passing experiment.
We propose a sampling-based grasp synthesis framework, GraspFlow, to generate context-specific grasps. We test GraspFlow in a real-world table-top grasping task.
We develop a family of stable continuous-time neural state space-models.
We contribute an empirical study into the effectiveness of LLMs, specifically GPT-3.5 variants, for the task of natural language goal translation to PDDL.
Transfer source policies to a target reinforcement learning task with safety constraints using Successor Features.
We examine the problem of observed adversaries for deep policies, where observations of other agents can hamper robot performance.
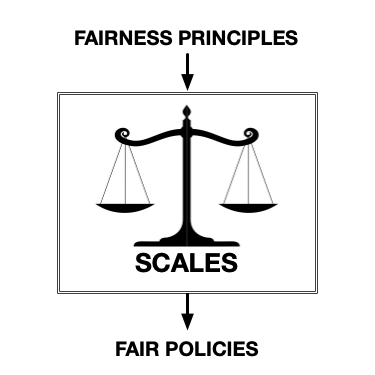
This paper proposes SCALES, a general framework that translates well-established fairness principles into a common representation based on CMDPs.
We develop an accurate physics-inspired model for describing how a population of Q-learning agents adapt as they interact.
Inspired by Social Projection Theory, we use the robot's self model to efficiently model humans.
We propose a deep switching state space model that can capture both state-dependent and time-dependent switching patterns in time series data.
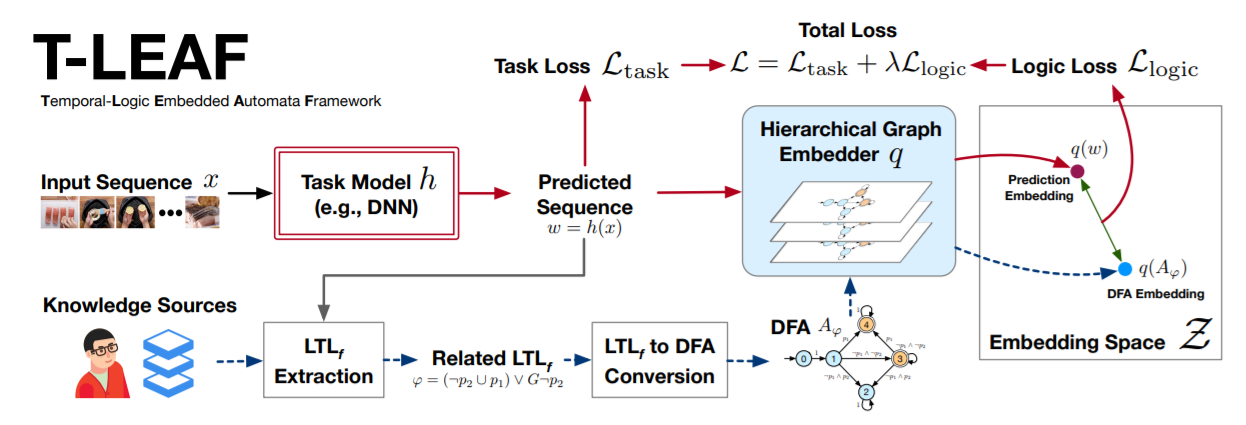
We embed symbolic knowledge expressed as linear temporal logic (LTL) and use these embeddings to guide the training of deep sequential models.
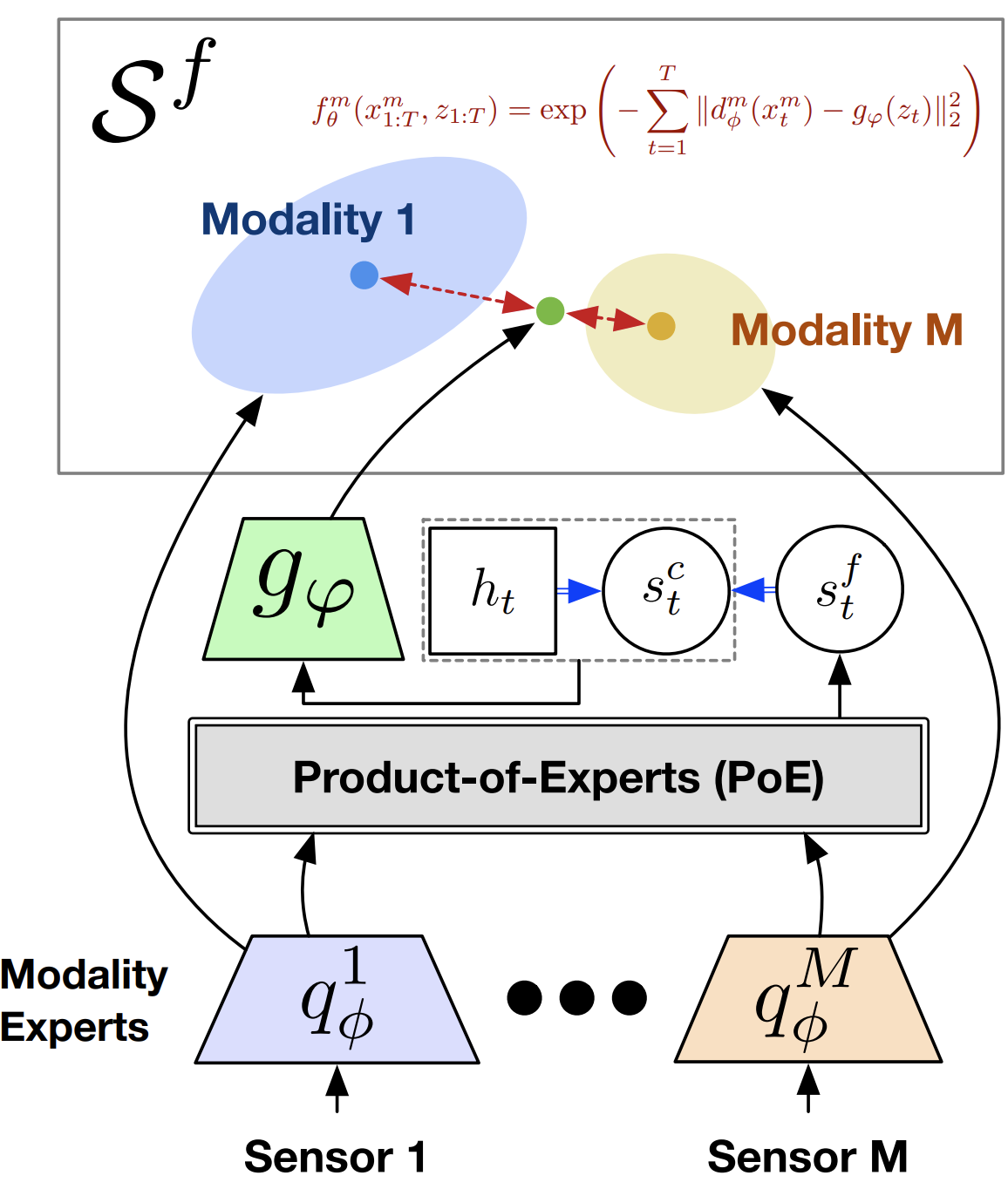
We construct a shared latent space from different sensory modalities via contrastive learning.
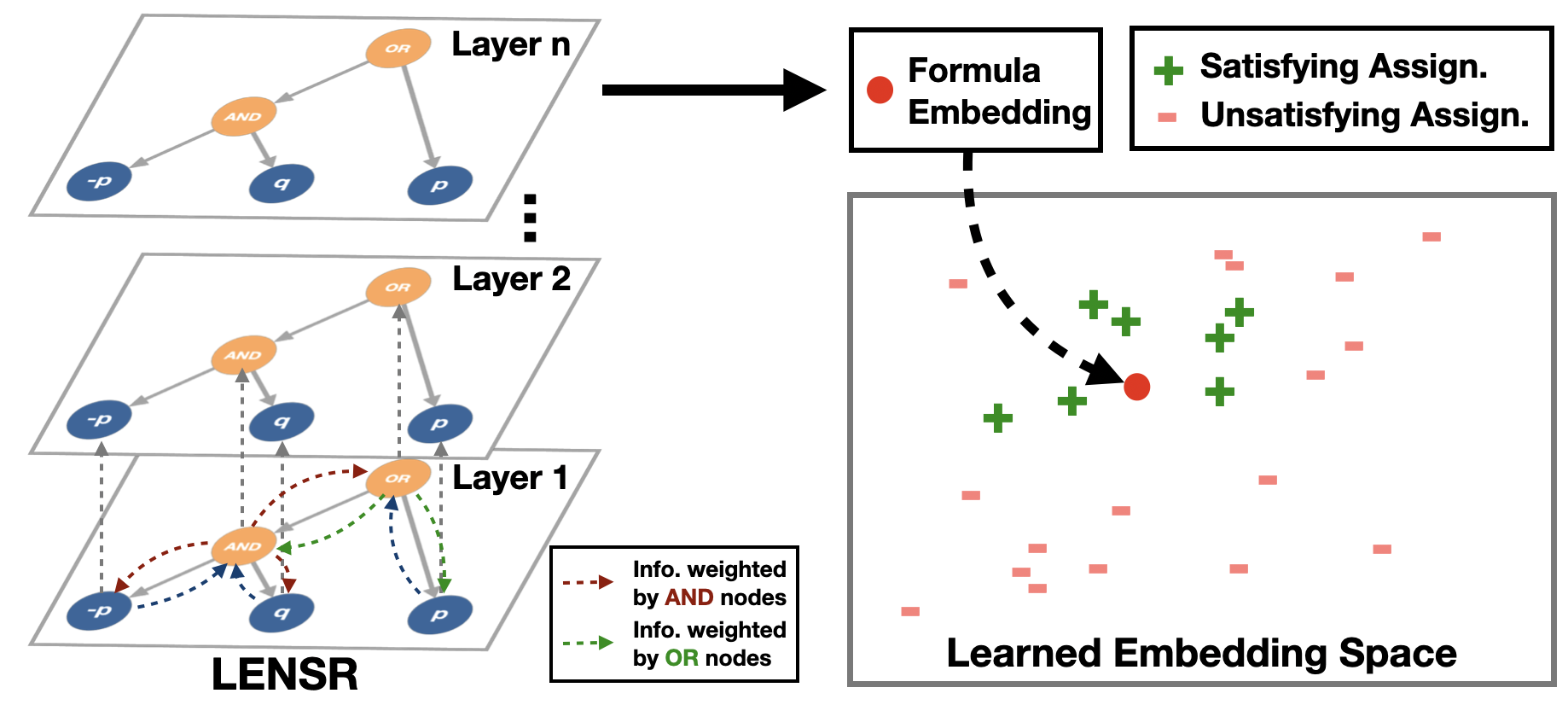
Bridging the gap between symbolic and connectionist paradigms via Graph Neural Network embeddings
We present a new method for training GANs via characteristic functions
Training robots that can interactively assist humans with private information
Leveraging prior symbolic knowledge to improve the performance of deep models.
We present an approach to generate new items for groups of users based on their interaction history.
Using Bayesian Optimization to address the ill-posed nature of Inverse Reinforcement Learning