
Communication is an essential skill for intelligent agents; it facilitates cooperation and coordination, and enables teamwork and joint problem-solving. However, effective communication is challenging for robots; given a multitude of information that can be relayed in different ways, how should the robot decide what, when, and how to communicate?
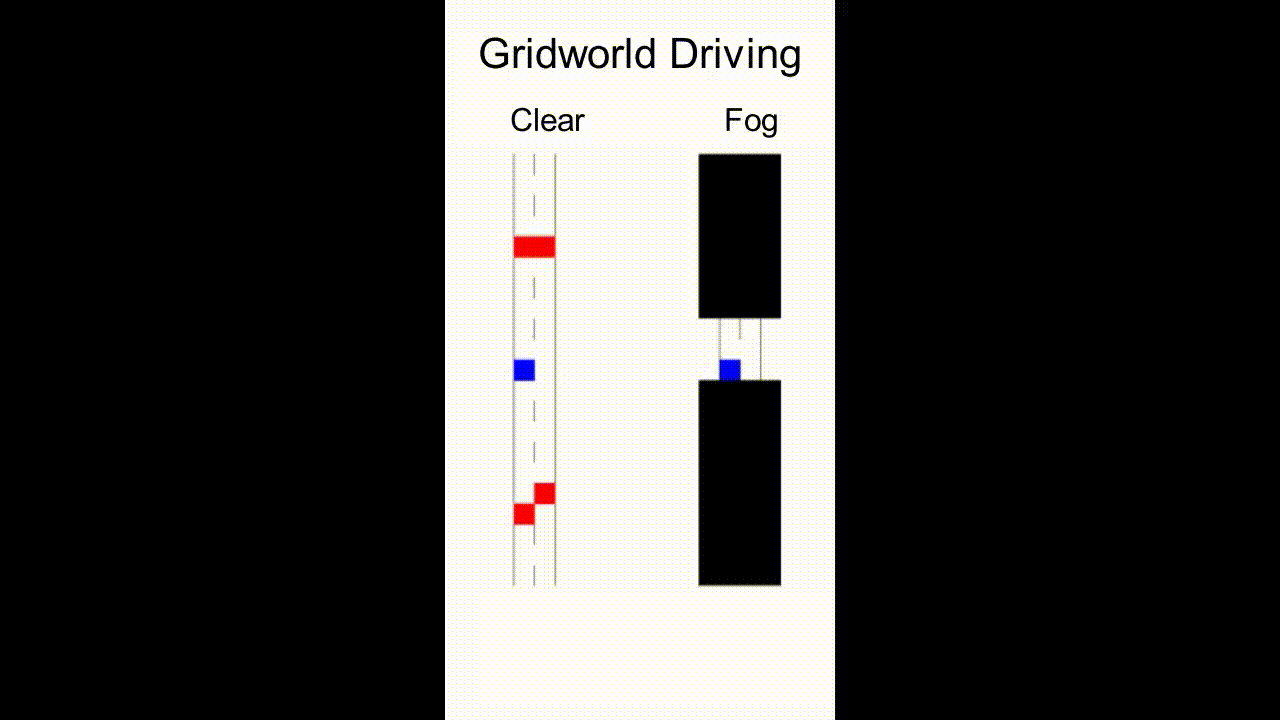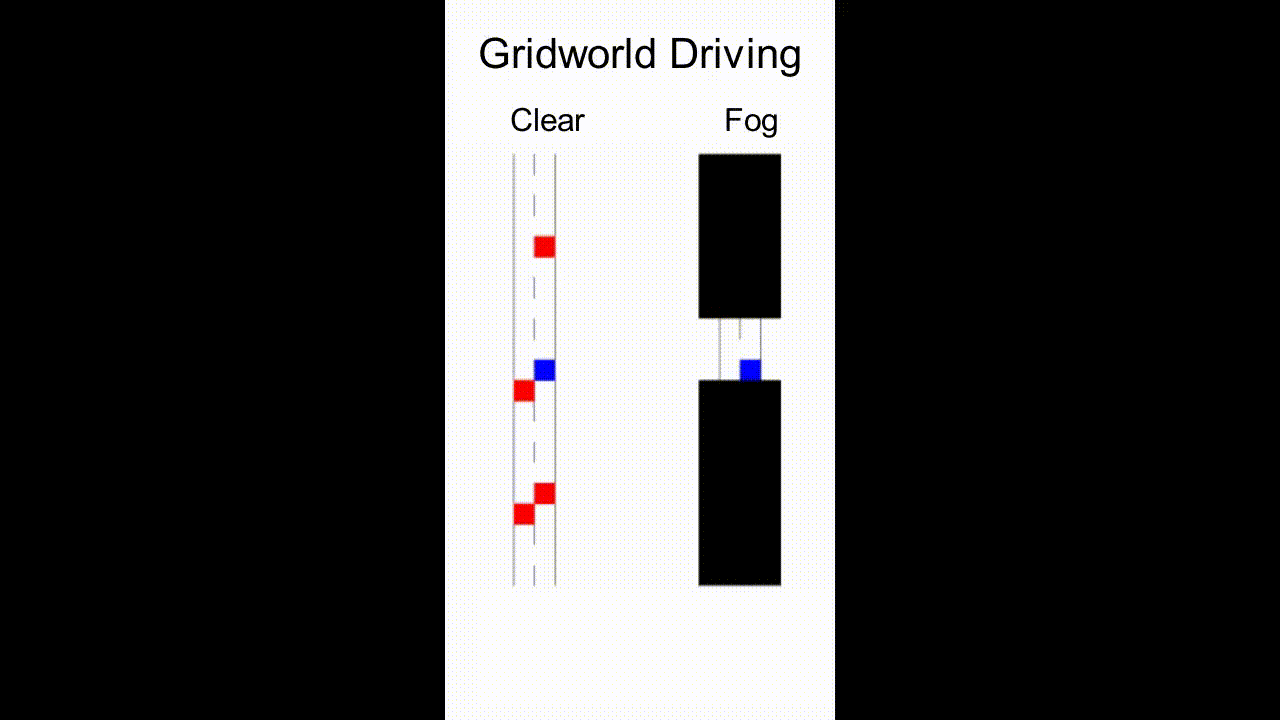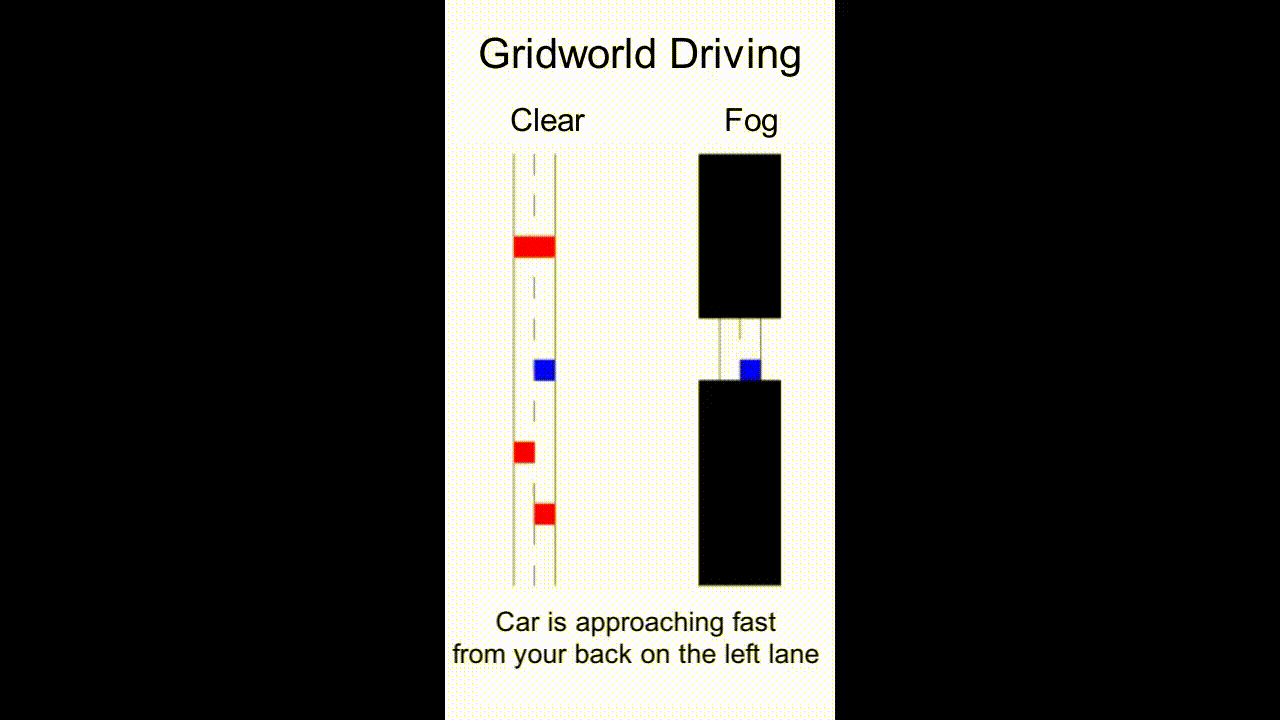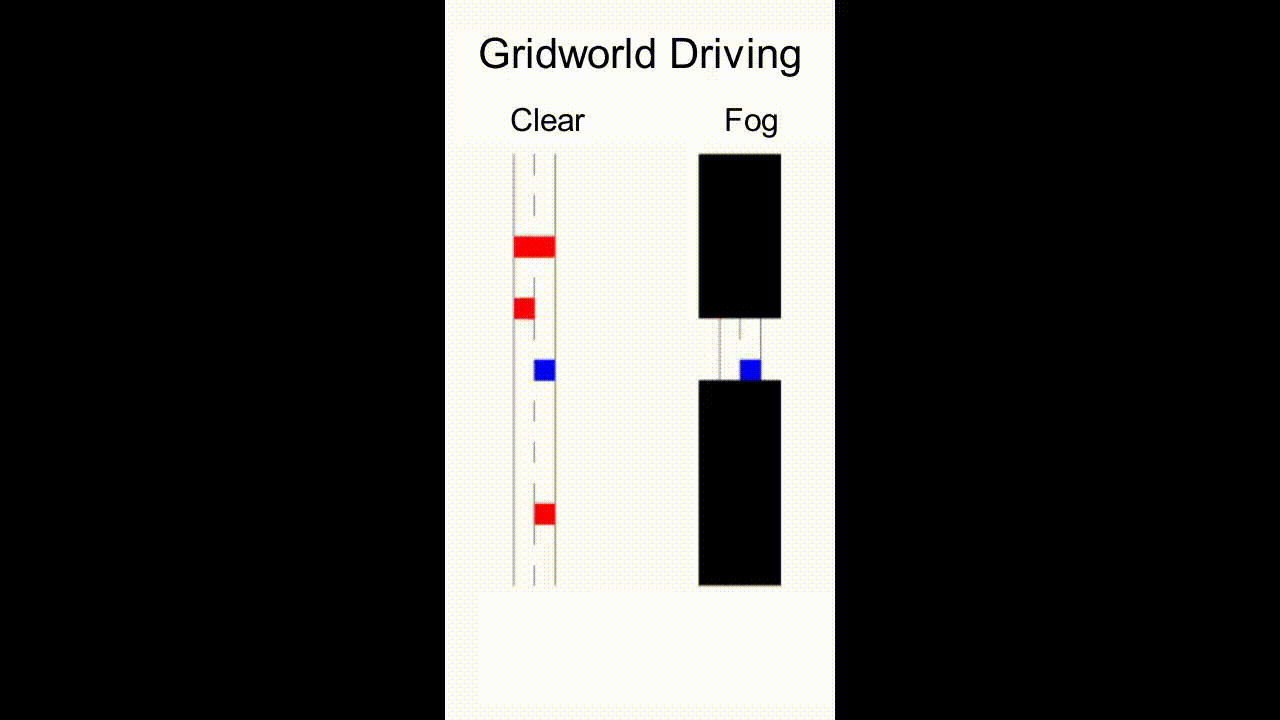
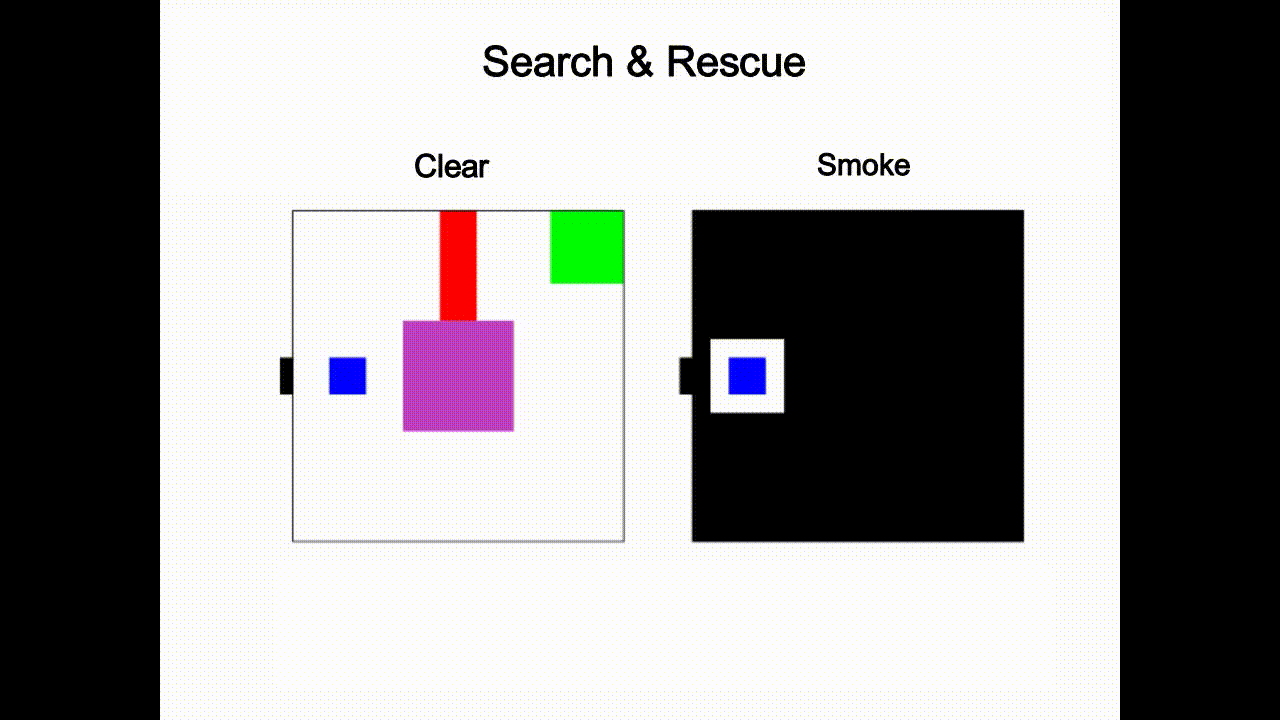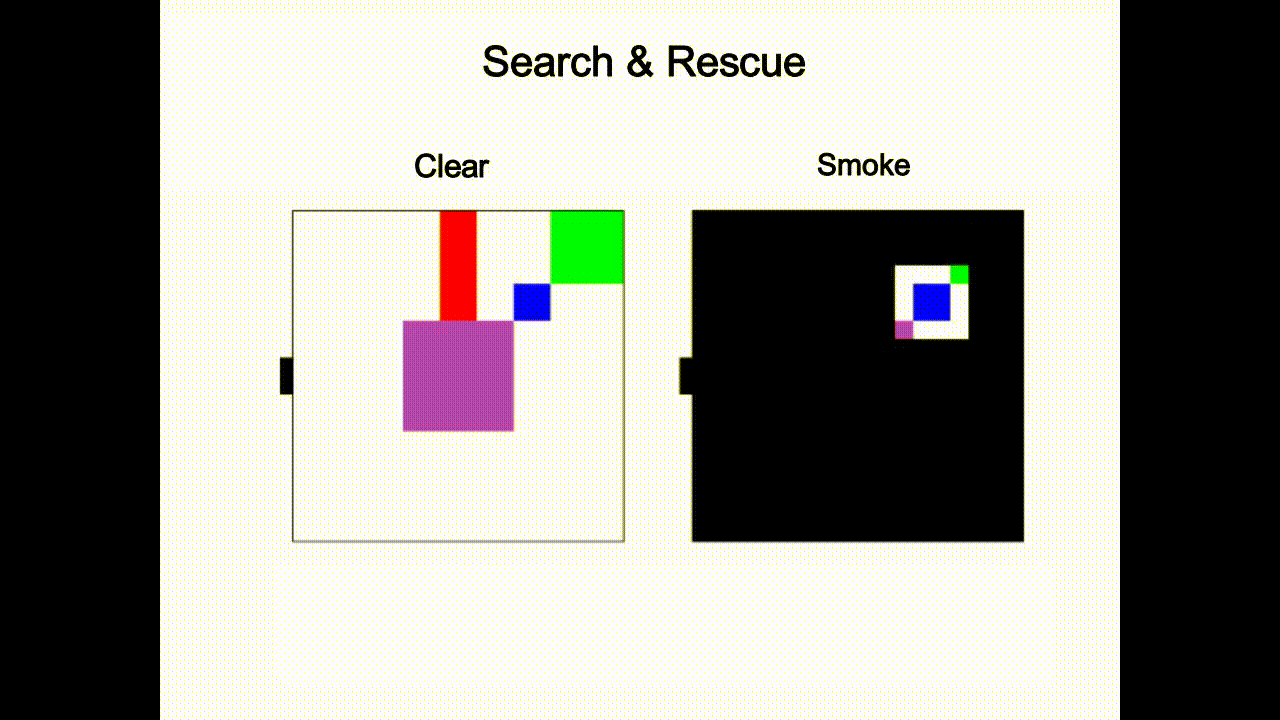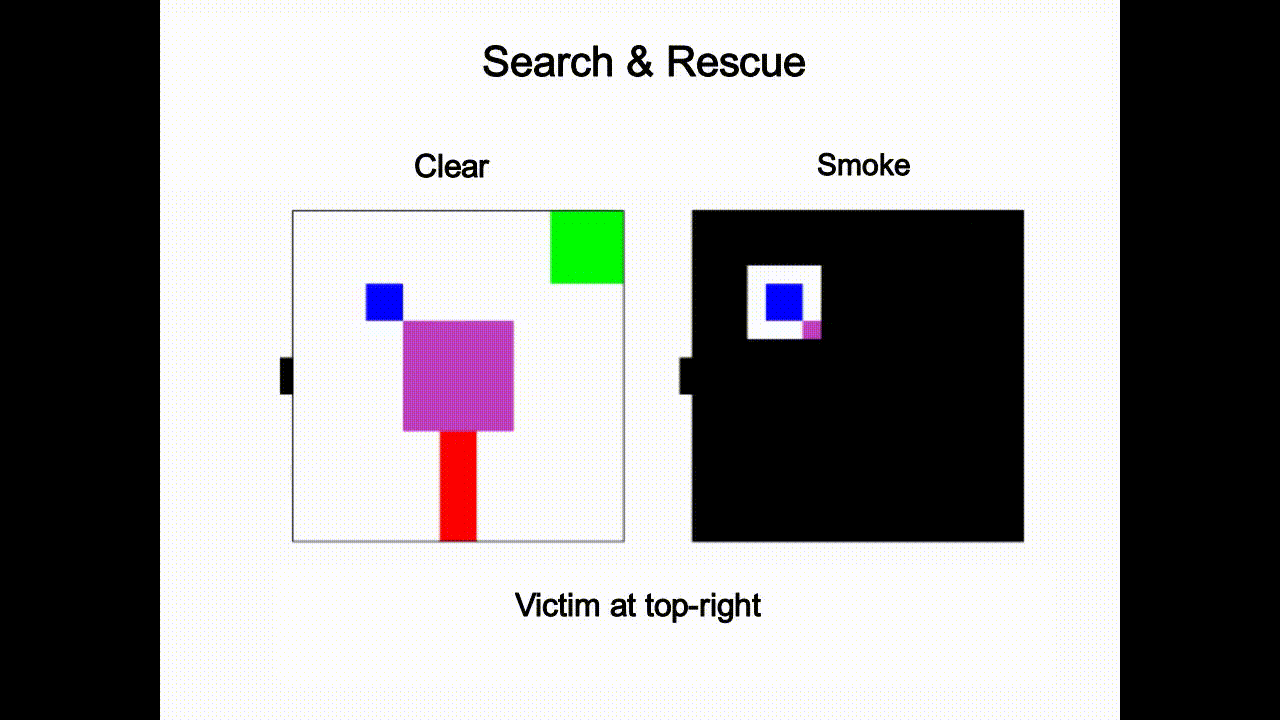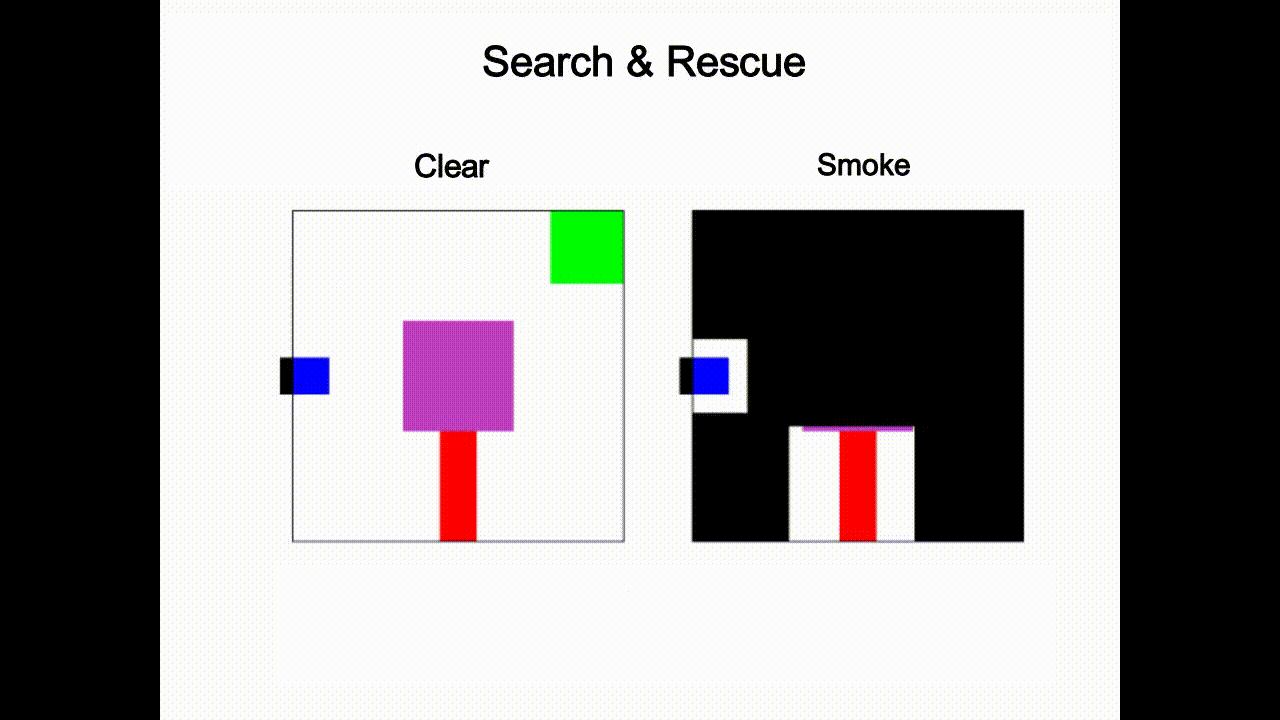
As an example, consider the scenario in Fig. 1 where a robot assistant is tasked to provide helpful information to a human driving the blue car in fog (or to explain the robot’s own driving behavior). There are other cars in the scene, which may not be visible to the human. The robot, however, has access to sensor readings that reveal the environment and surrounding cars. To prevent potential collisions, the robot needs to communicate relevant information — either using a heads-up display or verbally — that intuitively, should take into account what the human driver currently believes, what they can perceive, and the actions they may take.

Prior work on planning communication methods in HRI typically rely on human models, which are typically handcrafted using prior knowledge [1] or learned from collected human demonstrations [2]. Unfortunately, handcrafted models do not easily scale to complex real-world environments with high-dimensional observations, and data-driven models typically require a large number of demonstrations to generalize well. In this work, we seek to combine prior knowledge with data in a manner that reduces both manual specification and sample complexity.
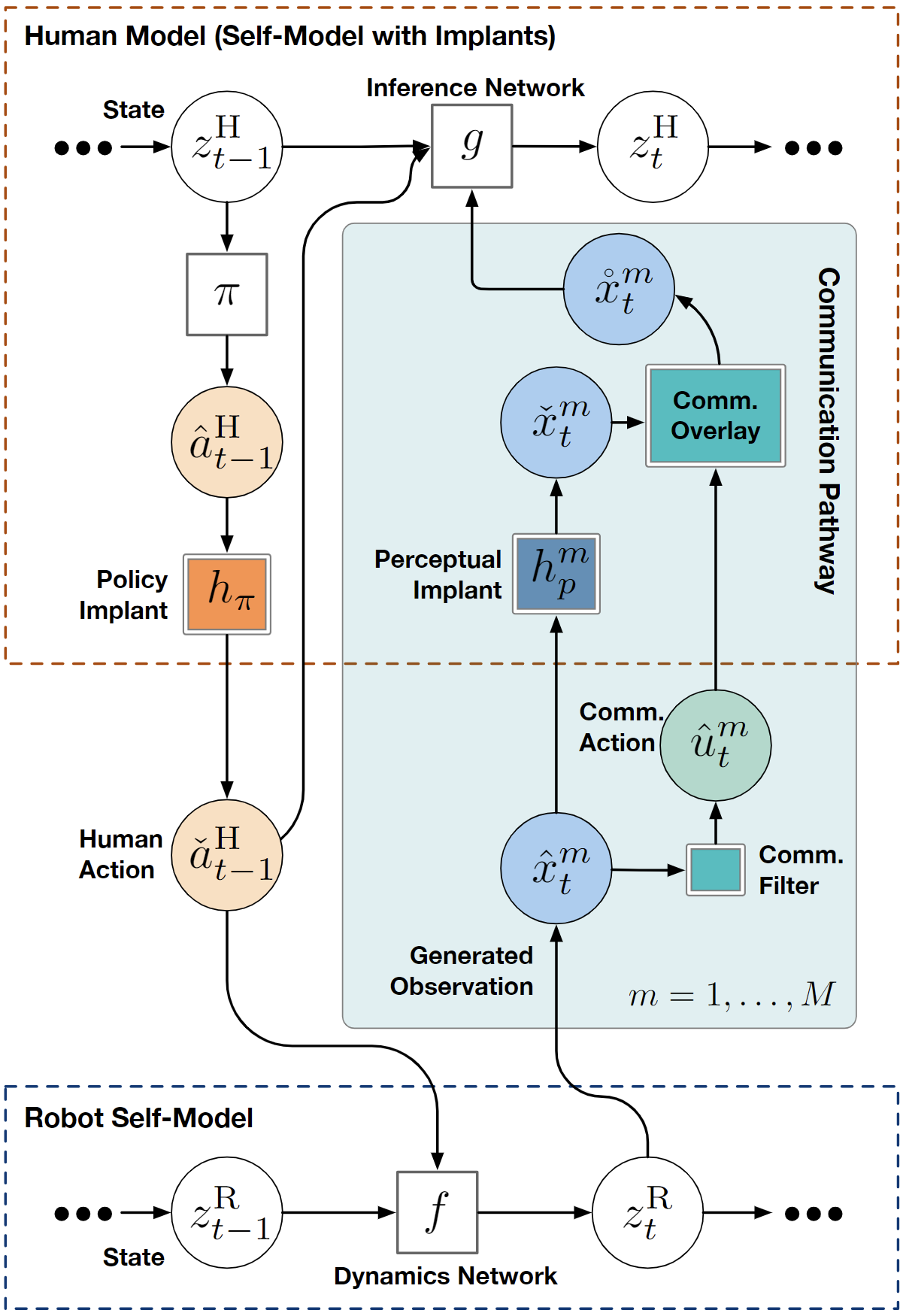
In this work, we seek to combine prior knowledge with data in a manner that reduces both manual specification and sample complexity. Our key insight is that learning differences from a suitable reference model is more data-efficient than learning an entire human model from scratch. We take inspiration from social projection theory [3], which suggests that humans have a tendency to expect others to be similar to ourselves, i.e., a person understands other individuals using one’s self as a reference. We leverage latent state-space models obtained via deep reinforcement learning as the initial model (robot’s self model). To capture the difference between robot and human models, we strategically place learnable implants, which are small functions that can be quickly optimized via gradient-based learning. We call our framework Model Implants for Rapid Reflective Other-agent Reasoning/Learning (MIRROR).
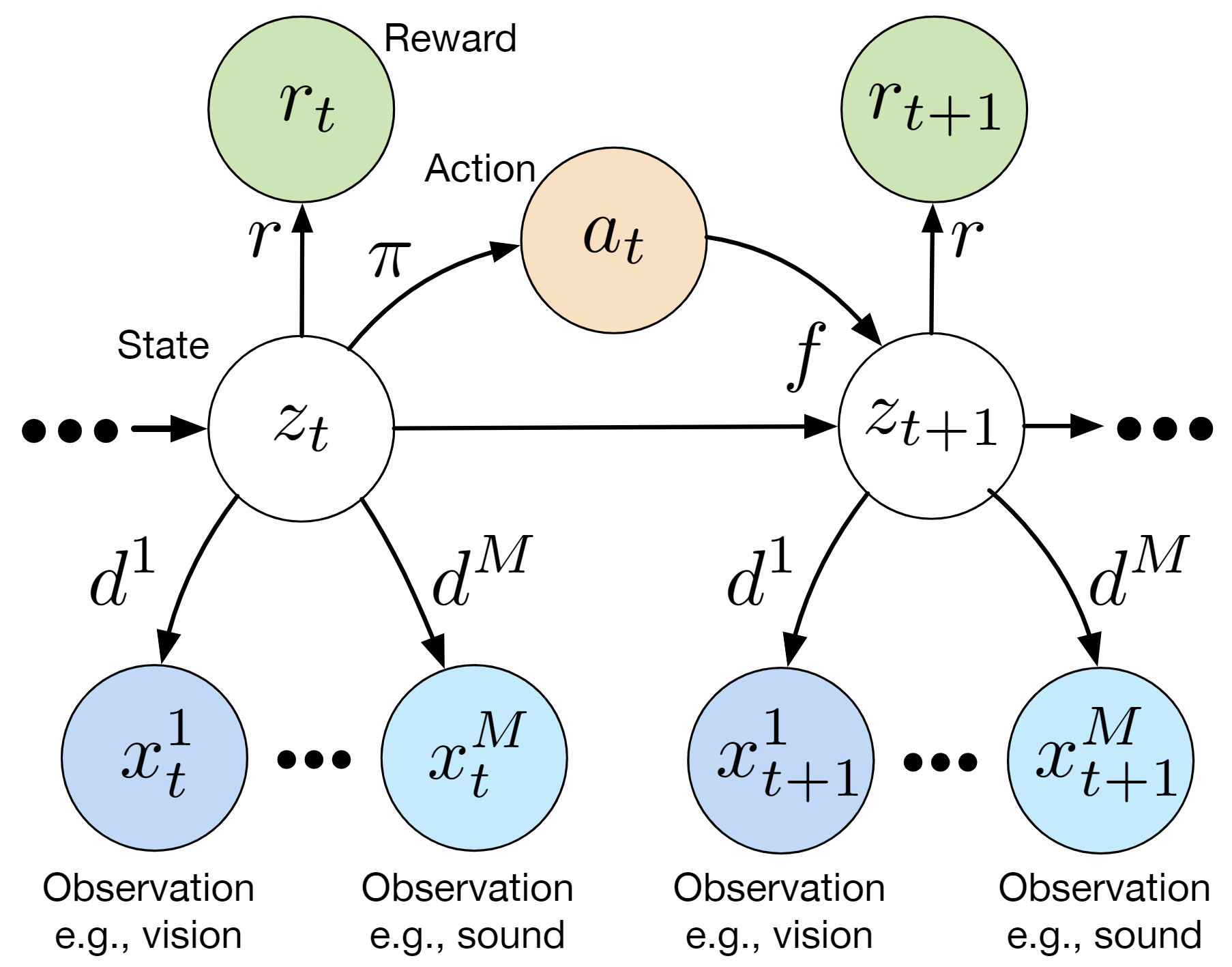
In MIRROR, the robot’s self-model is a multi-modal state-space model (Fig.2) and is optimized via ELBO loss:
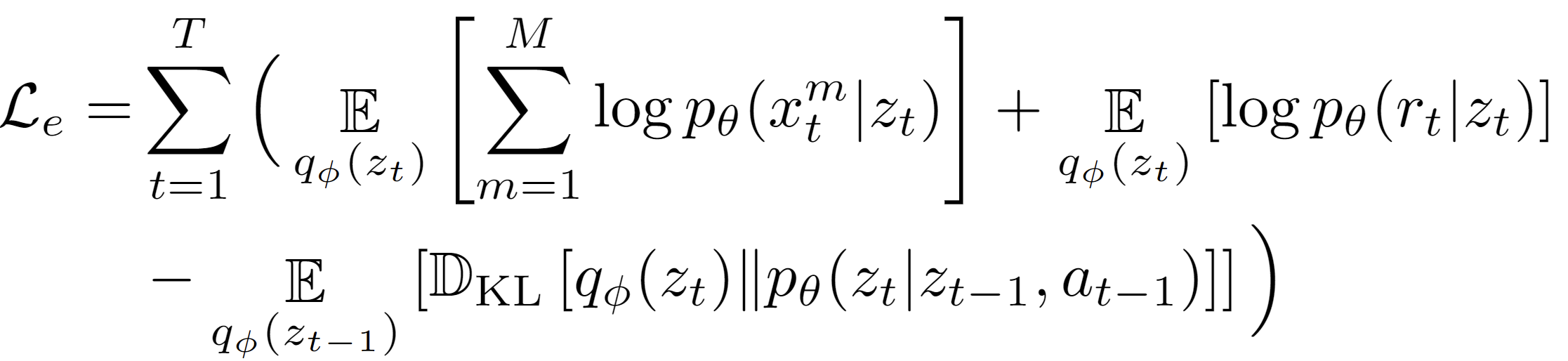
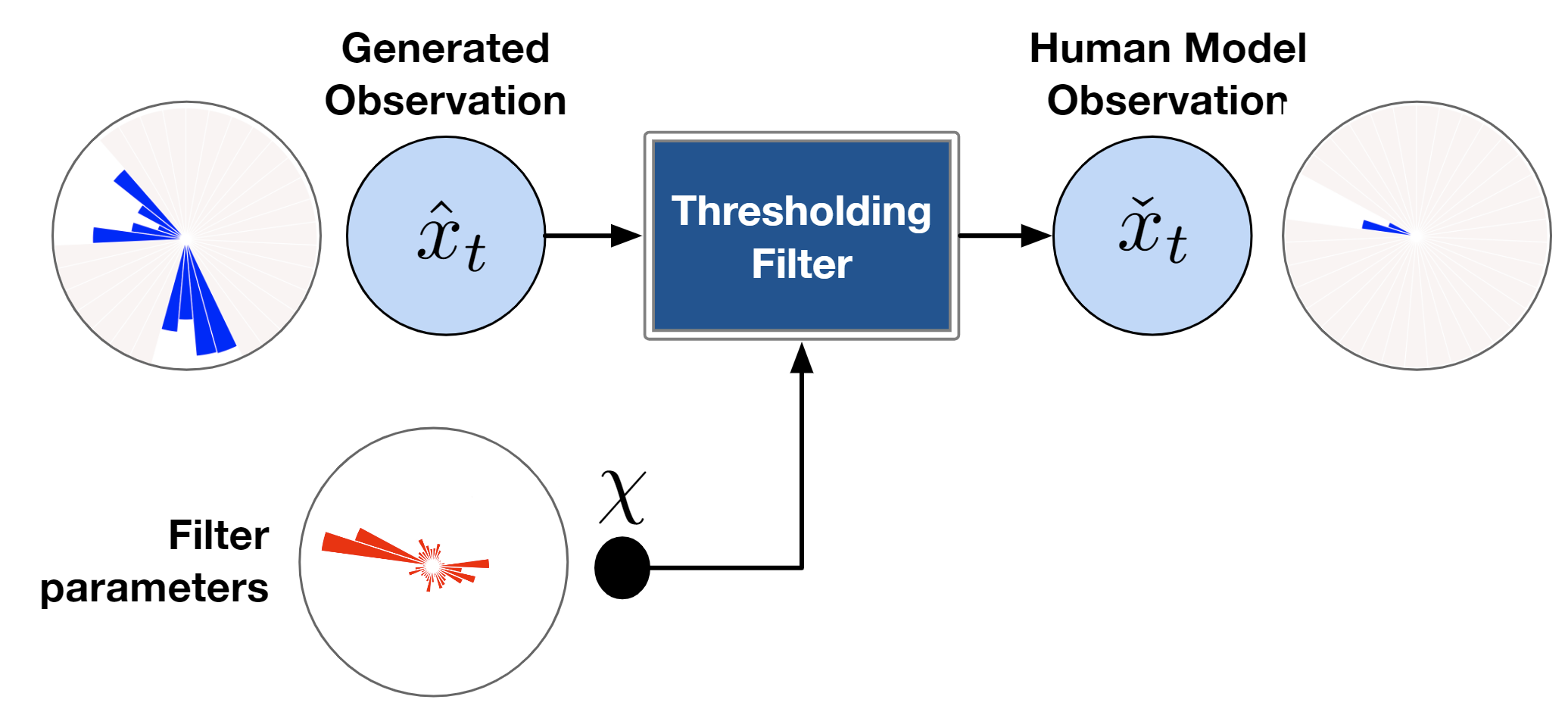
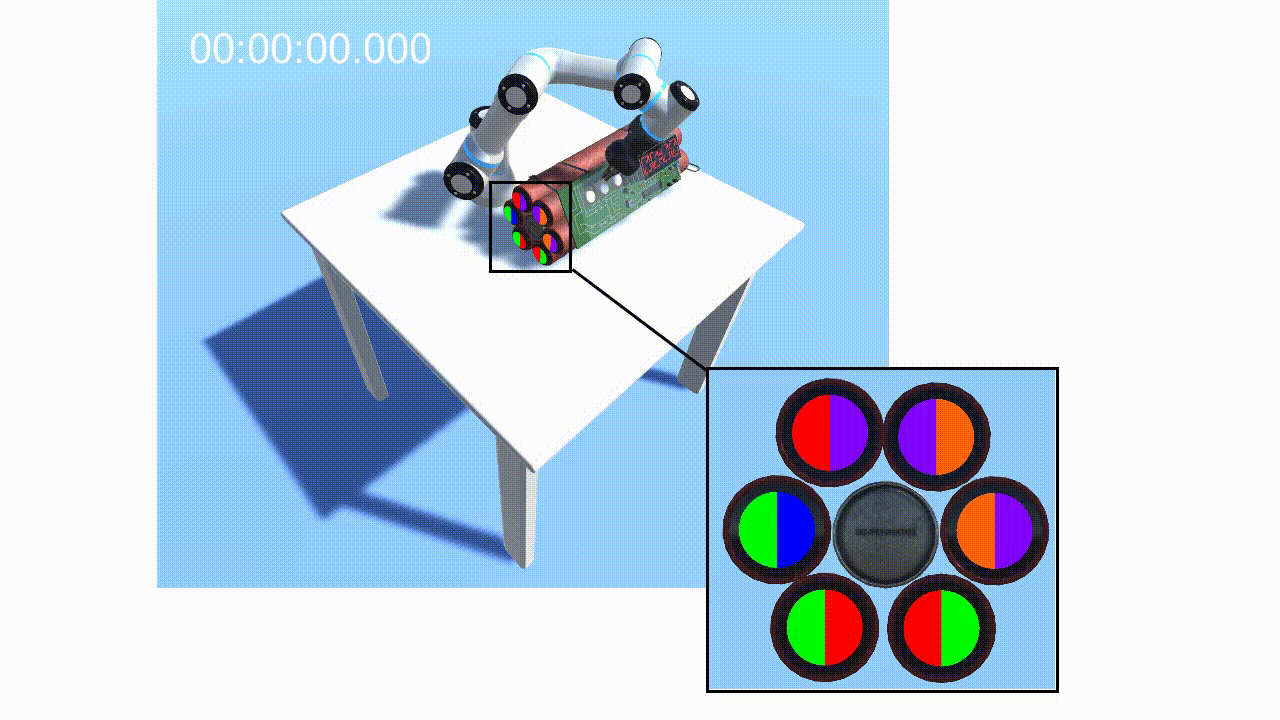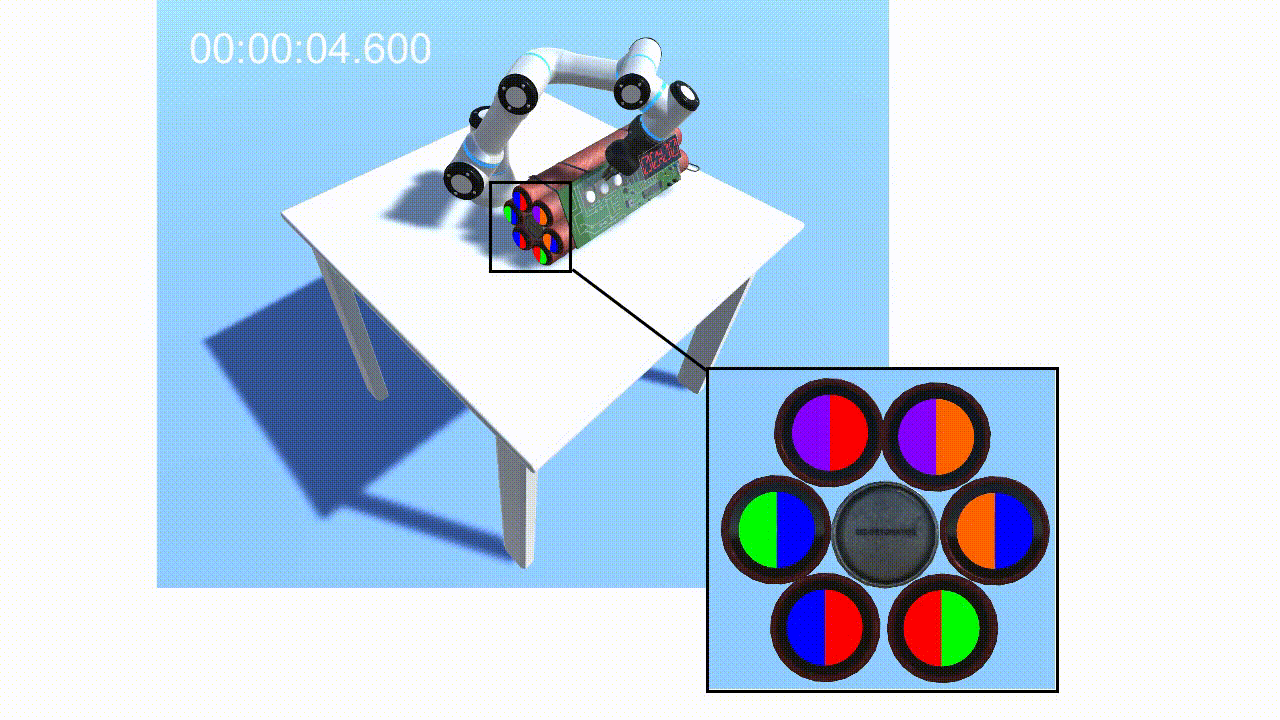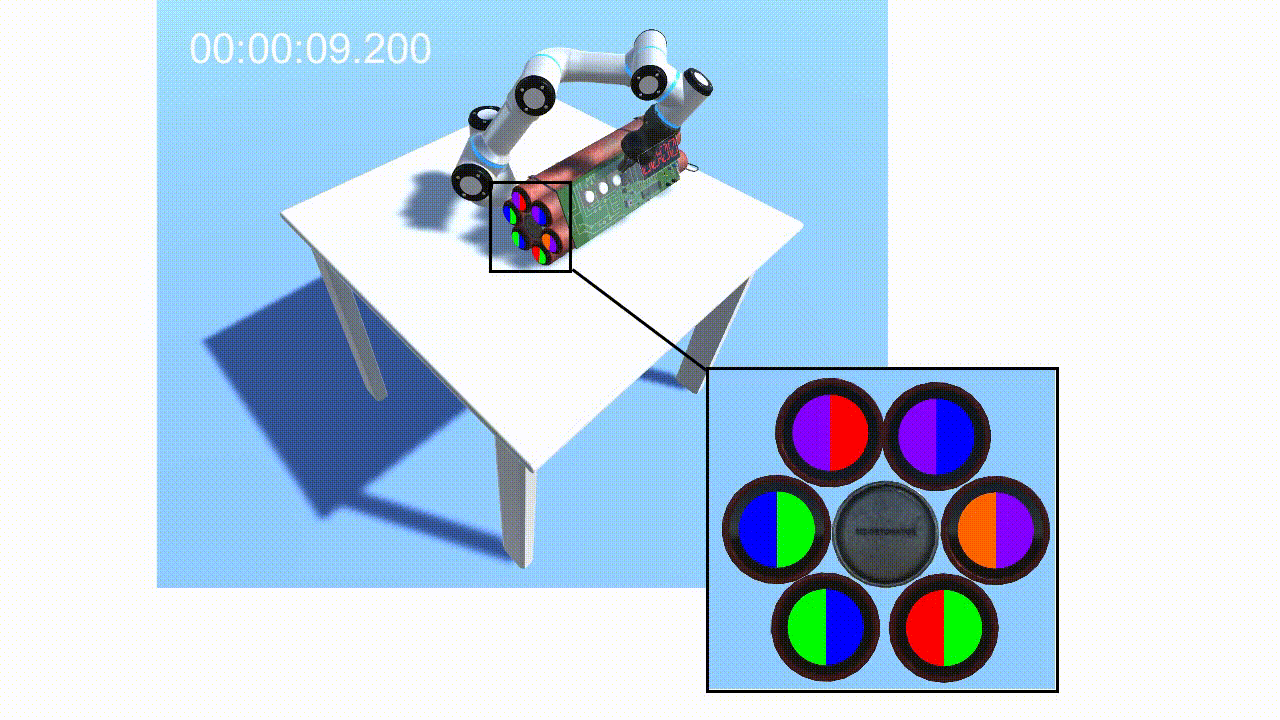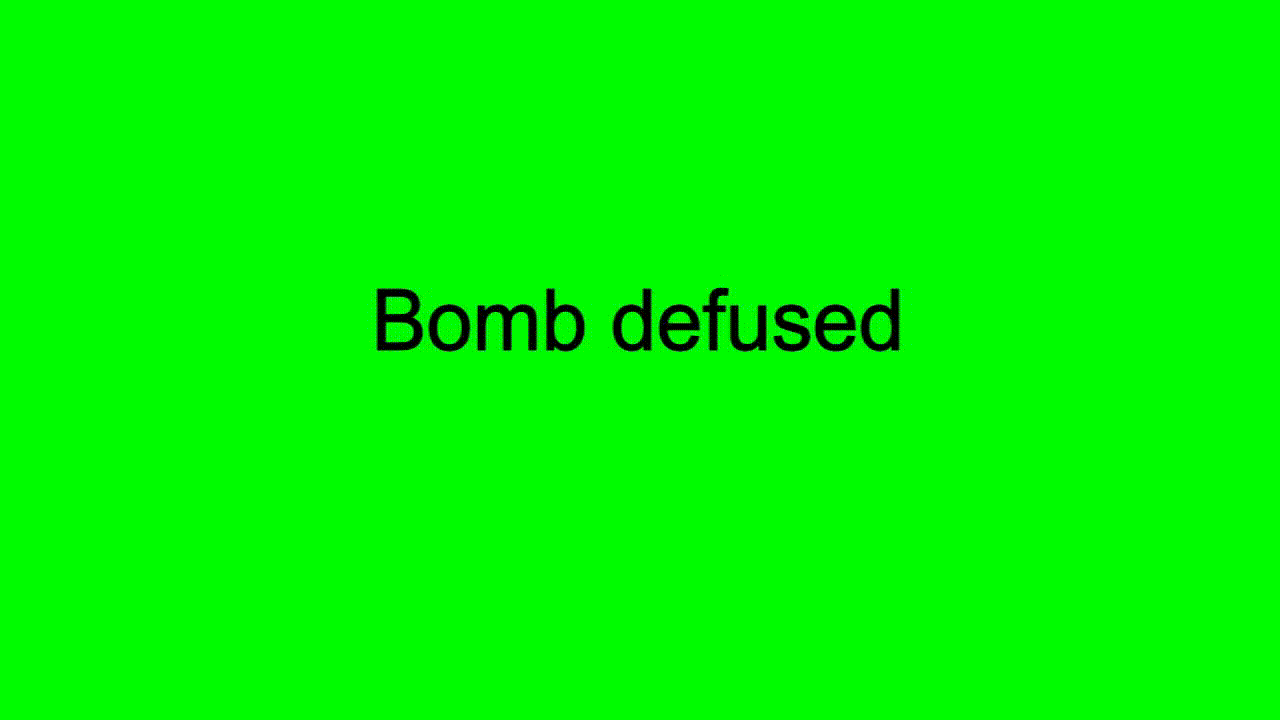
Given the latent states z sampled from the inference network, we leverage RL to learn optimal policies. Our approach is based on Stochastic Latent Actor Critic [4]. Once the self-model is trained, we augment it with implanted functions h(·) (e.g. perceptual implant and policy implant). Fig.3 gives an example of the perceptual implant. Given an implant hχ parameterized by χ, we can learn χ by minimizing the following loss given data:
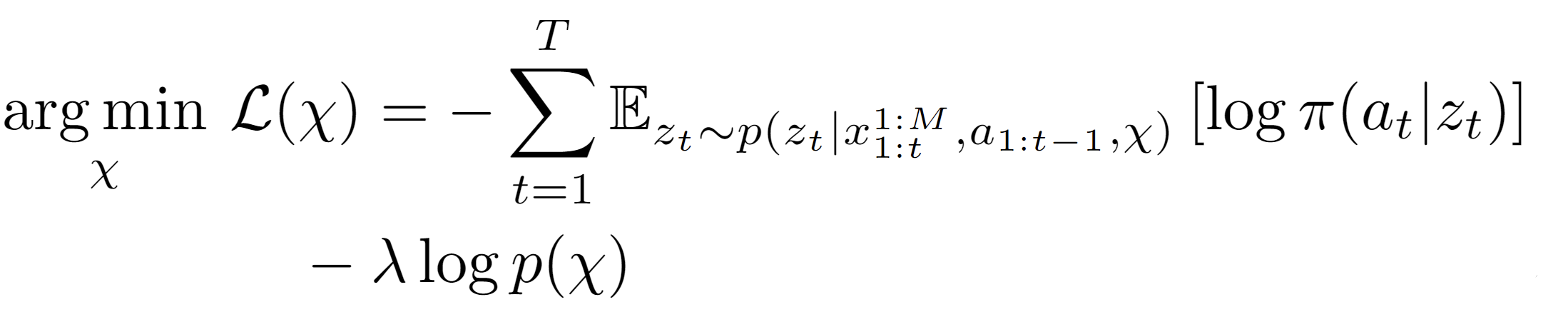
Finally, the robot can optimize communication to maximize task rewards while minimizing communication costs via forward simulation and communication pathways (Fig.4).
Experiments in three simulated domain show that MIRROR is able to learn better human models faster compared to behavioral cloning (BC) and a state-of-the-art imitation learning method. In addition, we report on a human-subject study using the CARLA simulator [5], which reveals that MIRROR provides useful assistive information, enabling participants to complete a driving task with fewer collisions in adverse visibility conditions. Participants also had a better subjective experience with MIRROR — they found MIRROR to be more helpful and timely —, which led to higher overall trust.


Code
Code for reproducing experiments presented in this paper can be found at this Github repo.
Citation
If you find our code or the ideas presented in our paper useful for your research, consider citing our paper.
Kaiqi Chen, Jeffrey Fong, and Harold Soh. “MIRROR: Differentiable Deep Social Projection for Assistive Human-Robot Communication” Robotics: Science and Systems, 2022.
@inproceedings{chen2022mirror,
title={MIRROR: Differentiable Deep Social Projection for Assistive Human-Robot Communication},
author={Chen, Kaiqi and Fong, Jeffrey and Soh, Harold},
year={2022},
booktitle = {Proceedings of Robotics: Science and Systems},
year = {2022},
month = {June}}
Contact
If you have questions or comments, please contact Kaiqi Chen.
Acknowledgements
This research is supported by the National Research Foundation Singapore under its AI Singapore Programme (Award Number: AISG-RP-2019-011).
References
[1] A. Tabrez, S. Agrawal, and B. Hayes, “Explanation-based reward coaching to improve human performance via reinforcement learning,” in 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 2019, pp. 249–257.
[2] S. Reddy, A. D. Dragan, and S. Levine, “Sqil: Imitation learning via reinforcement learning with sparse rewards,” in International Conference on Learning Representations, 2019.
[3] F. H. Allport, Chapter 13: Social Attitudes and Social Consciousness, ser. Social Psychology. Houghton Mifflin Company, 1924.
[4] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Offpolicy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning. PMLR, 2018, pp. 1861–1870.
[5] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” in Proceedings of the 1st Annual Conference on Robot Learning, 2017, pp. 1–16.





{kind=link}