
In this work, we focus on learning useful and robust deep world models using multiple, possibly unreliable, sensors. We find that methods by maximizing a reconstruction-based variational evidence lower-bound (ELBO) do not sufficiently encourage a shared representation between modalities; this can cause poor performance on downstream tasks and over-reliance on specific sensors.
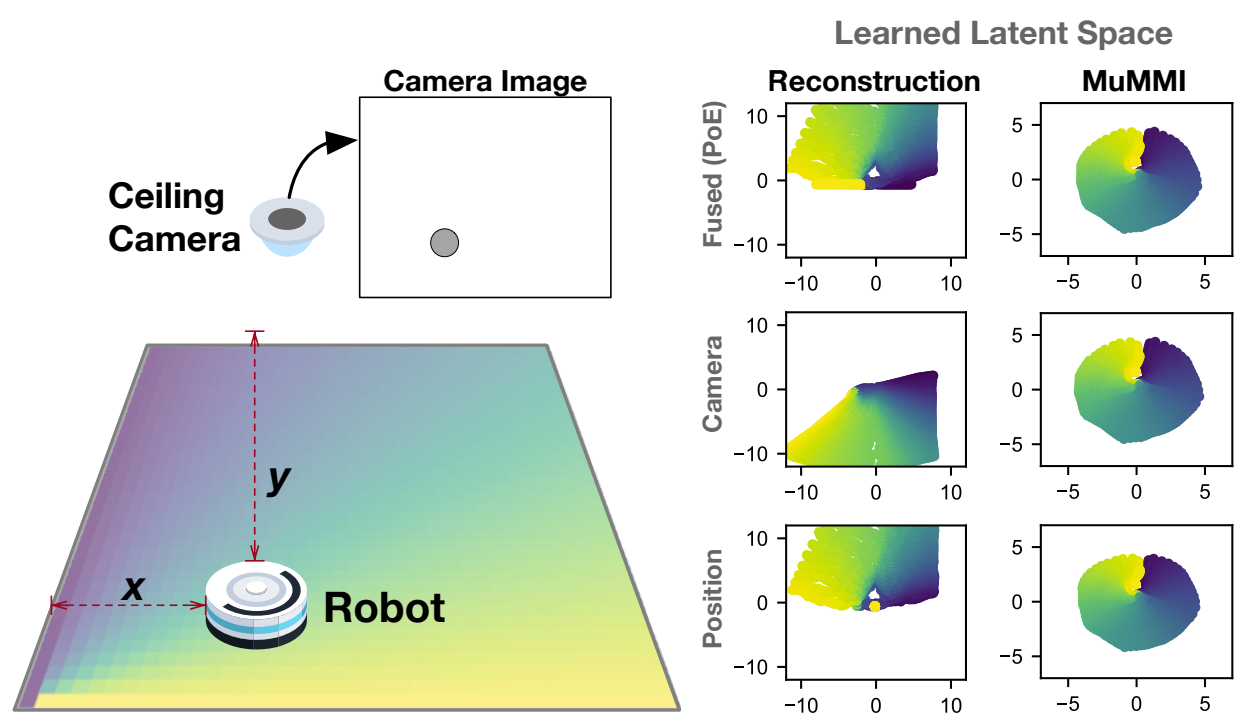
A simple illustrative example of a robot in a 2D world with two sensory modalities: laser rangers that give its (x, y) position and a ceiling camera provides a scene image. A Deep Latent Space Model (SSM) trained using Product-of-Experts (PoE) fusion and a reconstruction-based loss did not learn a robust latent space from gathered data (left plots, colors indicate ground-truth position): the overlap between the two modality-specific latent spaces is small and model is over-reliant on the position sensor.
The experts were “miscalibrated” in that the camera expert predicts a much higher variance relative to the position expert and thus, has little influence during PoE fusion.
Our technique MuMMI encourages a consistent latent space across the different modalities (right plots) with calibrated experts.
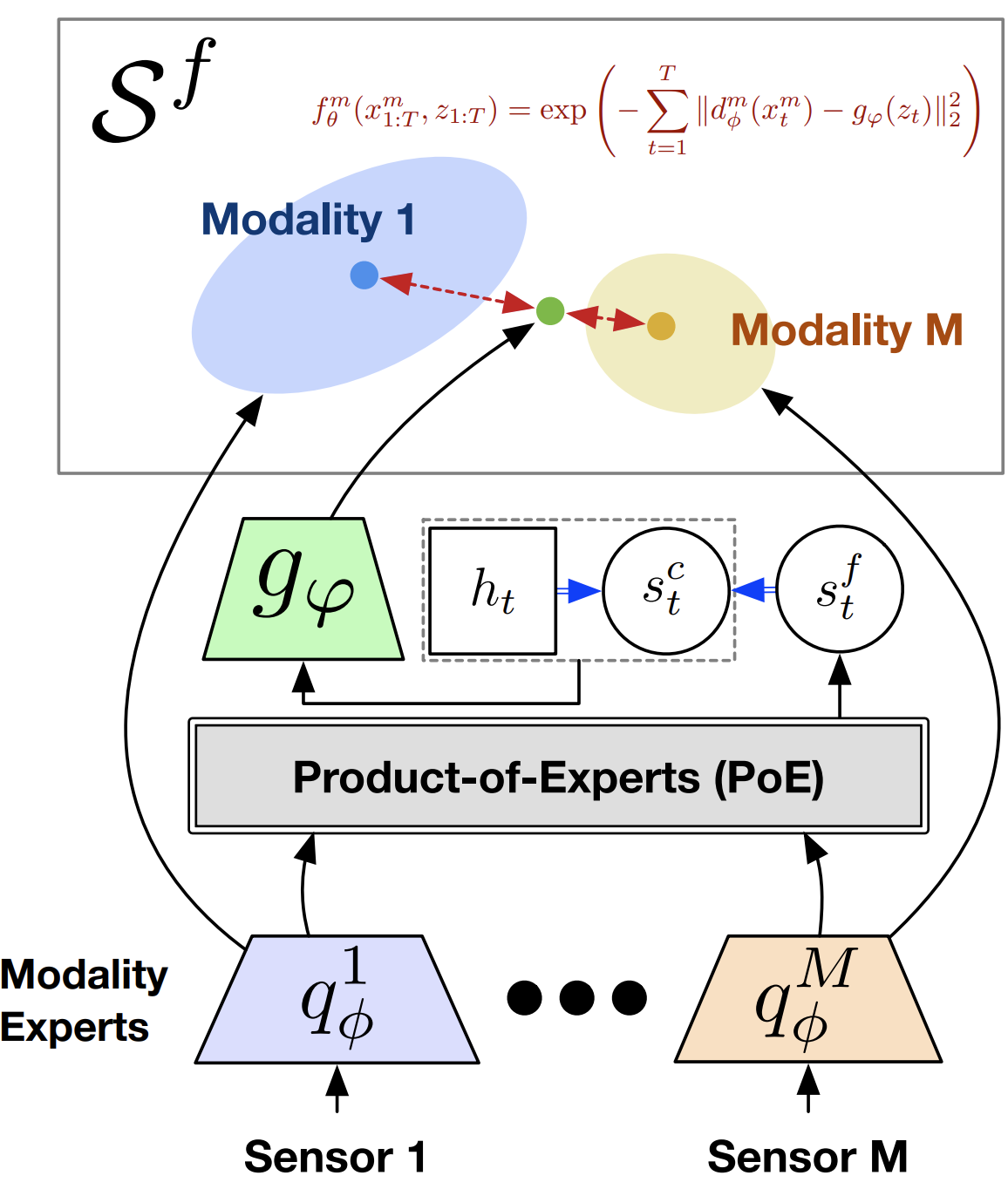
MuMMI uses MI-based lower-bound that is optimized via the InfoNCE loss. Within this contrastive framework, we explicitly encourage the different modality networks to be consistent with one another via a specially-designed density ratio estimator.
Our final loss is
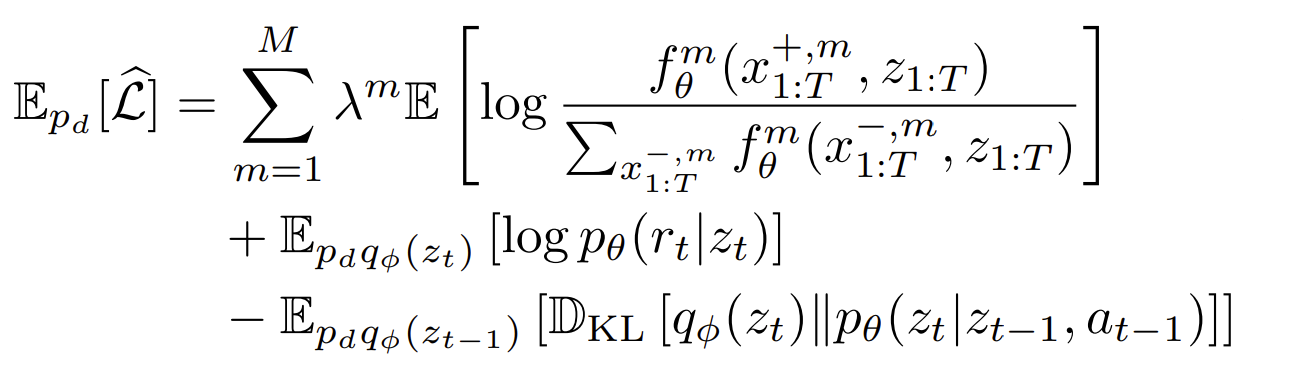
and it lower bounds the log-likelihood of observations and rewards.
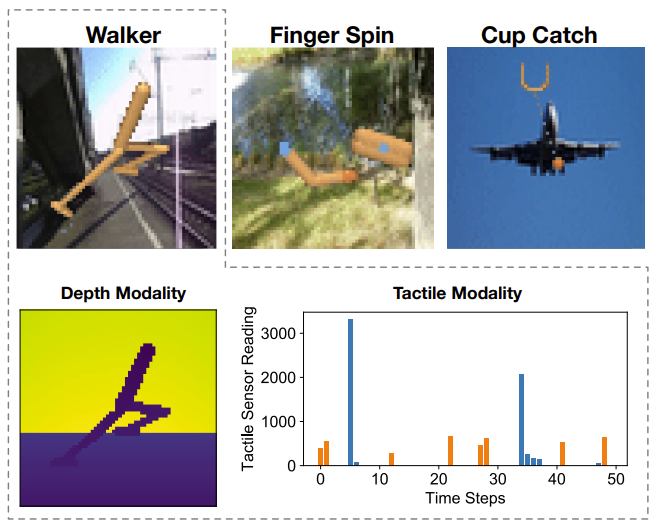
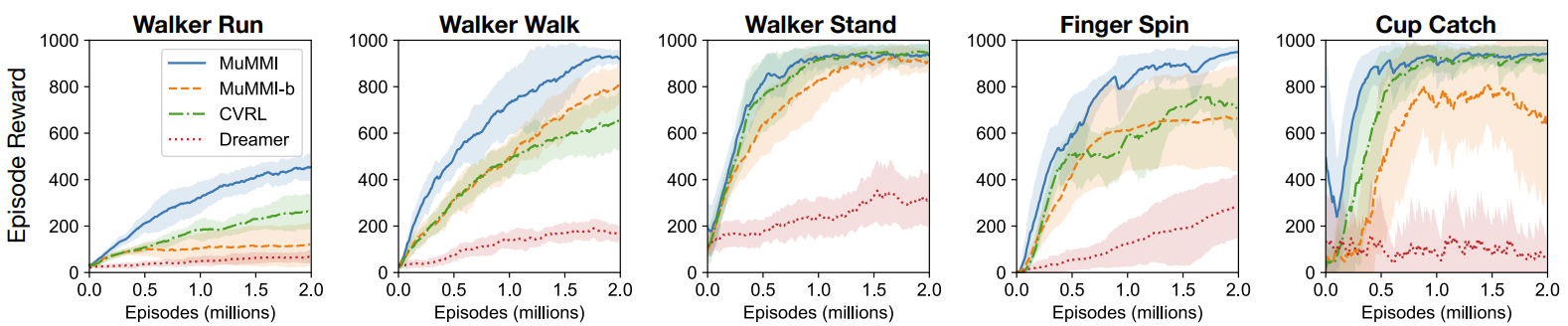
We tasked our method to learn policies (in a self-supervised manner) on multi-modal Natural MuJoCo benchmarks and a challenging Table Wiping task. Experiments show our method significantly outperforms state-of-the-art deep reinforcement learning methods, particularly in the presence of missing observations.
Code
Code for reproducing experiments presented in this paper can be found at this Github repo.
Citation
If you find our code or the ideas presented in our paper useful for your research, consider citing our paper.
Kaiqi Chen, Yong Li, and Harold Soh. “Multi-Modal Mutual Information (MuMMI) Training for Robust Self-Supervised Deep Reinforcement Learning” International Conference on Robotics and Automation, 2021.
@inproceedings{Chen2021MuMMI,
title={Multi-Modal Mutual Information (MuMMI) Training for Robust Self-Supervised Deep Reinforcement Learning},
author={Kaiqi Chen and Yong Lee and Harold Soh},
year={2021},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)}}
Contact
If you have questions or comments, please contact Kaiqi Chen.
Acknowledgements
This work was supported by the Science and Engineering Research Council, Agency of Science, Technology and Research, Singapore, through the National Robotics Program under Grant No. 192 25 00054.
References
[1] D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” arXiv preprint arXiv:1912.01603, 2019.
[2] X. Ma, S. Chen, D. Hsu, and W. S. Lee, “Contrastive variational model-based reinforcement learning for complex observations,” arXiv preprint arXiv:2008.02430, 2020.





{kind=link}