
VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback, Jianxin Bi★, Kevin Yuchen Ma, Ce Hao★, Mike Shou Zheng, and Harold Soh★, IEEE Robotics and Automation Letters (RA-L)
Links:
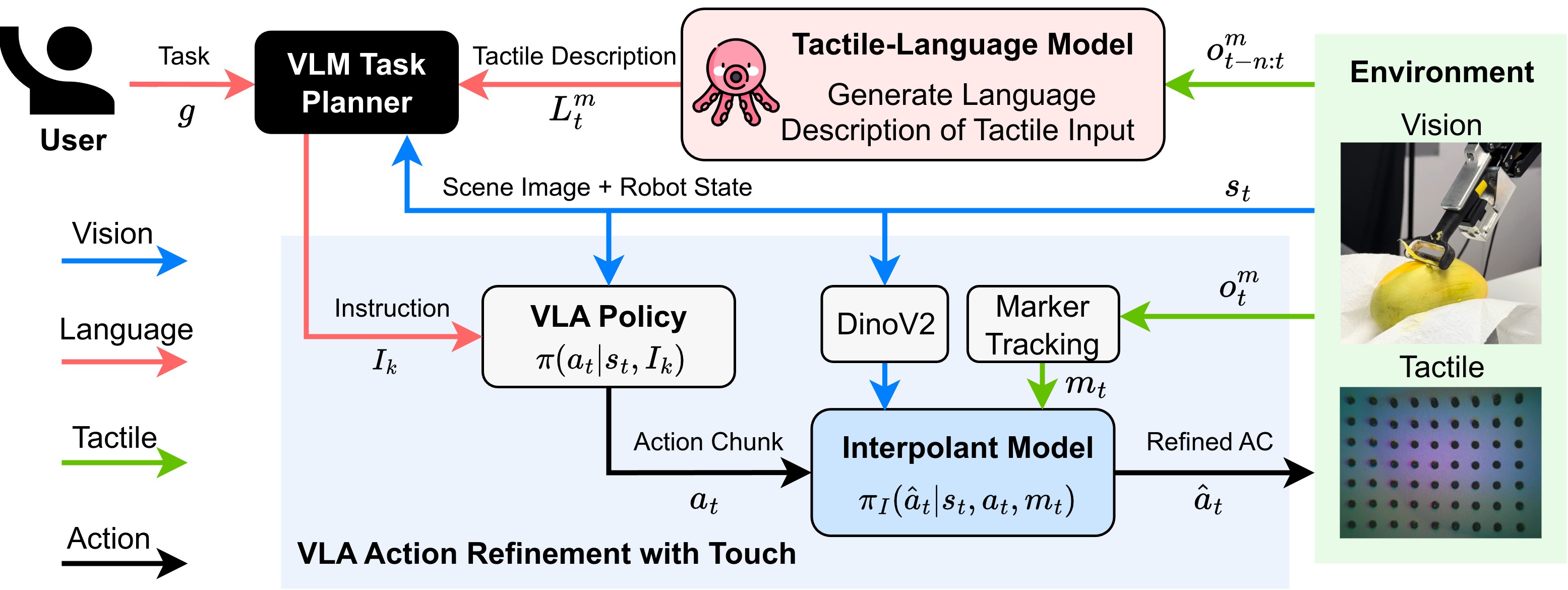
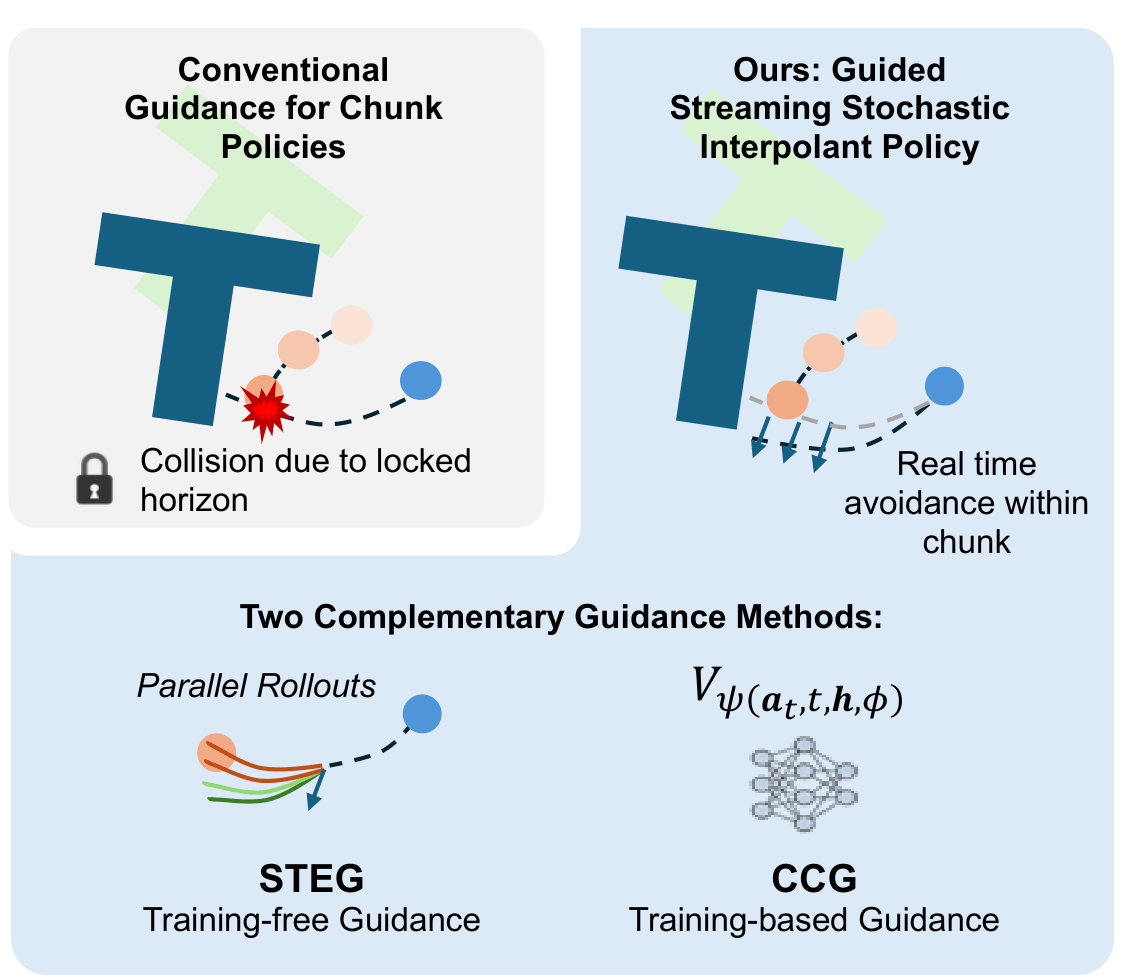
Abstract: Tactile feedback is generally recognized to be crucial for effective interaction with the physical world. However, state-of-the-art Vision-Language-Action (VLA) models lack the ability to interpret and use tactile signals, limiting their effectiveness in contact-rich tasks. Incorporating tactile feedback into these systems is challenging due to the absence of large multi-modal datasets. We present VLA-Touch, an approach that enhances generalist robot policies with tactile sensing without fine-tuning the base VLA. Our method introduces two key innovations: (1) a pipeline that leverages a pretrained tactile-language model that provides semantic tactile feedback for high-level task planning, and (2) a diffusion-based controller that refines VLA-generated actions with tactile signals for contact-rich manipulation. Through real-world experiments, we demonstrate that our dual-level integration of tactile feedback improves task planning efficiency while enhancing execution precision.
Resources
You can find our paper, check out our project page and code!
Citation
Please consider citing our paper if you build upon our results and ideas.
Jianxin Bi★, Kevin Yuchen Ma, Ce Hao★, Mike Shou Zheng, and Harold Soh★, “VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback”, IEEE Robotics and Automation Letters (RA-L)
@article{bi2026vlatouch, title = {VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback}, author = {Bi, Jianxin and Ma, Kevin Yuchen and Hao, Ce and Shou, Mike Zheng and Soh, Harold}, journal = {IEEE Robotics and Automation Letters}, volume = {11}, number = {7}, pages = {8487--8494}, year = {2026}, doi = {10.1109/LRA.2026.3692345}, }
Contact
If you have questions or comments, please contact Jianxin or Harold.





{kind=link}