Introducing Dr. Alvin Heng!
Alvin Heng has graduated and is now Dr. Heng. Congratulations Alvin!

Laruso blog features productivity, tips, inspiration and strategies for massive profits. Find out how to set up a successful blog or how to make yours even better!
We introduce Arena 5.0, the fifth iteration of the Arena platform, featuring photorealistic simulation via NVIDIA Isaac Gym, comprehensive benchmarking, and customizable scenario generation!
We present a robust navigation framework designed for global deployment that achieved first place in the Earth Rover Challenge at ICRA 2025.
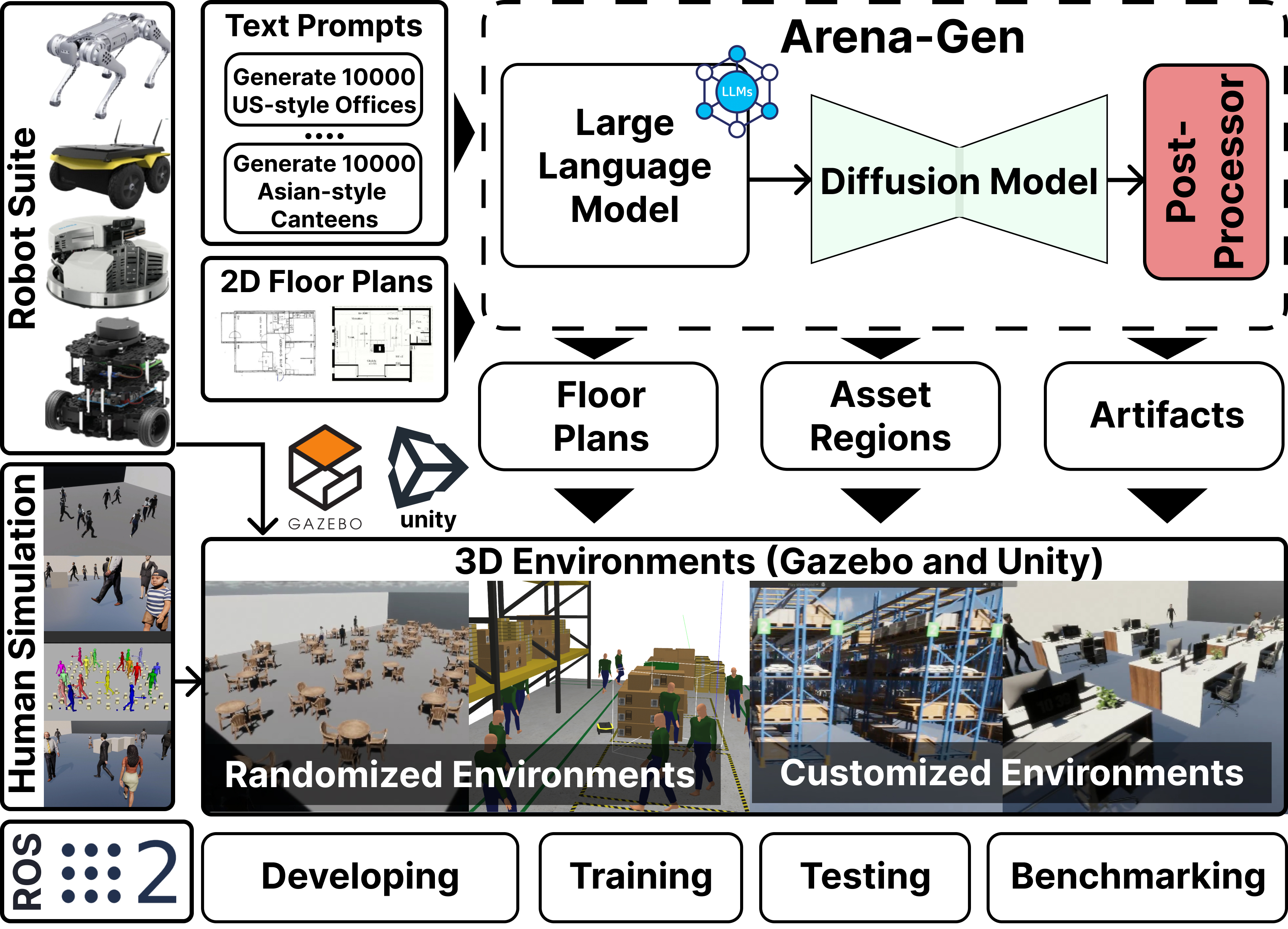
We introduce the fourth iteration of the Arena platform - Arena 4.0, a platform to develop, train, and benchmark social navigation approaches with generative model–based environment generation!
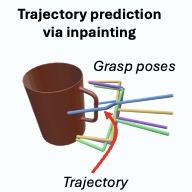
DISCO uses vision-language models to guide diffusion policies with optimized keyframe inpainting, enabling superior zero-shot open-vocabulary robotic manipulation.
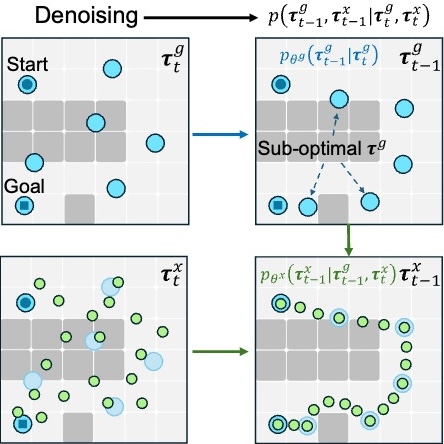
We propose CHD, a unified diffusion-based framework that tightly couples sub-goal and trajectory generation to improve long-horizon task planning.
We present VLA-Touch, a framework for VLA models with dual-level tactile feedback for contact-rich manipulation.